
L’objectif de ce tutoriel est de vous permettre de réaliser l’installation complète de Apache Hadoop sous Ubuntu.
Dans le cas présent, les versions utilisées sont les suivantes: Hadoop en version 3.3.3 et Ubuntu 22.01.
Ce tutoriel se veut être pédagogique. C’est pour cela que nous allons détailler chacune des étapes de l’installation.
Une fois arrivé à la fin de ce tutoriel, vous disposerez d’un environnement complet pour commencer à tester vos développements Hadoop.
Cet article fait partie d’un ensemble d’articles sur l’écosystème Hadoop.
Etapes de l’installation
Voici les étapes nécessaires pour réaliser notre installation de Apache Hadoop:
- Vérifier les prérequis
- Créer un groupe d’utilisateur Hadoop
- Configurer SSH
- Télécharger Hadoop
- Ajouter les variables d’environnement pour Hadoop
- Configurer les composants Hadoop
- Initialiser le système de fichier HDFS
- Démarrer le serveur Hadoop
- Tester l’installation
- Arrêter le serveur Hadoop
Vérifier les prérequis
Hadoop a deux prérequis: Java et SSH.
Si vous disposez déjà de Java 8 et de SSH sur votre machine, vous pouvez ignorez les deux paragraphes suivants.
Avant de commencer les installations sur Ubuntu, mettez à jour le cache des paquets de vos dépôts avec la commande:
sudo apt-get updateJAVA
Hadoop est développé en Java d’où le besoin qu’une version compatible soit installée sur votre machine. Pour connaître la version de Java compatible avec la version d’Hadoop, il est conseillé de consulter la page wiki d’Hadoop. Dans ce tutoriel, nous allons installer Hadoop en version 3.3.3 supporté par Java 8. Pour commencer, ouvrez un terminal et entrez les commandes suivantes:
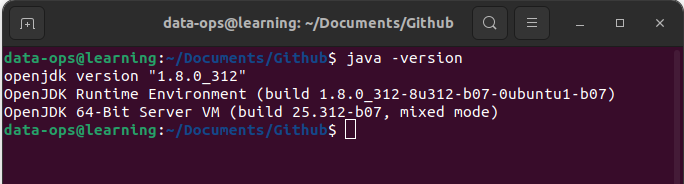
sudo apt install openjdk8-jdkUne fois l’installation de Java terminée, utilisez la commande « java -version » pour vérifier que Java est installé en version 8. Cette commande doit vous retourner un message dans votre terminal du type:
SSH
Pour utiliser les scripts de lancement et d’arrêt des démons d’Hadoop, vous devez installer SSH. Pour cela, tapez la commande suivante dans un terminal:
sudo apt install sshCréer un groupe d’utilisateur Hadoop
Bien que cette étape soit facultative, elle permet de séparer les installations de logiciels pour assurer la sécurité et gérer les permissions. Ainsi, il est conseillé de créer un groupe hadoop et un utilisateur spécifique hdoop avec un accès administrateur. Cela est réalisé avec les trois commandes suivantes:
sudo addgroup hadoop
sudo adduser --ingroup hadoop hdoop
sudo usermod -aG sudo hdoopUne fois l’utilisateur hdoop créé, connectez vous avec cet utilisateur de la façon suivante:
su - hdoopConfigurer SSH
Hadoop a besoin d’un accès SSH à tous les nœuds. Même en mode pseudo distribué sur un seul nœud, on doit donner accès au localhost à l’utilisateur hdoop. Pour cela, nous allons commencer par générer une clé SSH pour l’utilisateur hdoop avec la commande suivante:
ssh-keygen -t rsa -P ''Puis nous devons autoriser l’accès SSH au localhost pour cette nouvelle clé RSA:
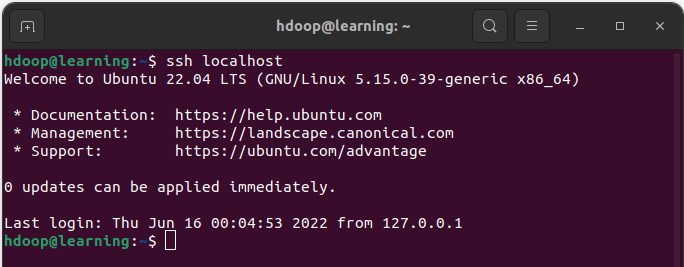
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysEnfin, vous pouvez vérifier que la connexion SSH au localhost pour l’utilisateur hdoop fonctionne correctement avec la commande « ssh localhhost » qui devra vous retourner un message du type:
Télécharger Hadoop
Il est conseillé d’utiliser le site officiel d’Apache Hadoop pour télécharger une version stable de Hadoop. Dans ce tutoriel, nous allons utiliser le binaire de Hadoop en version 3.3.3.
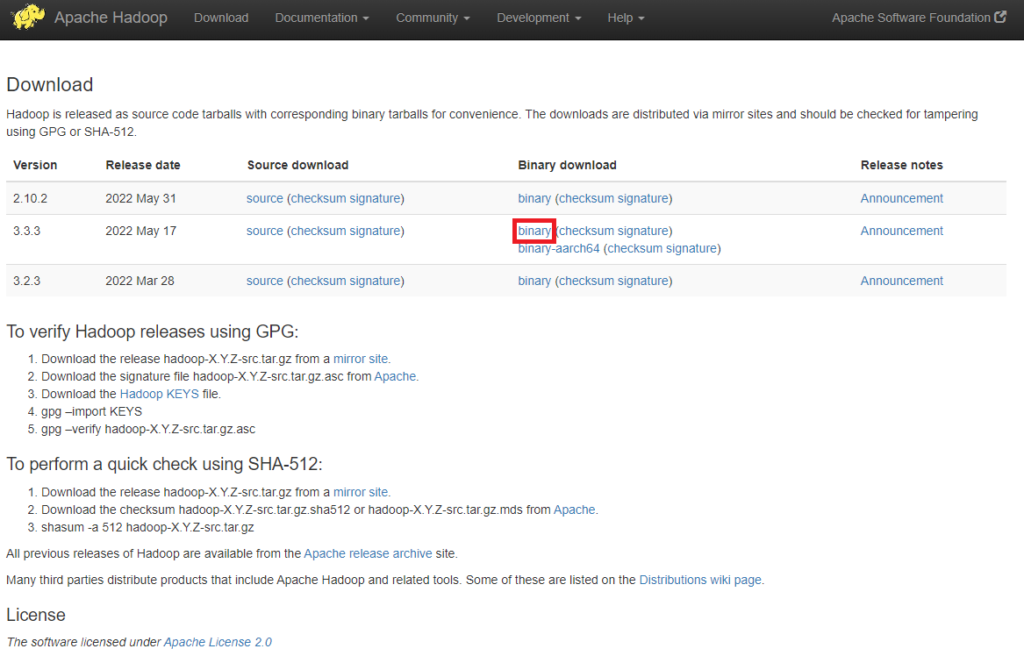
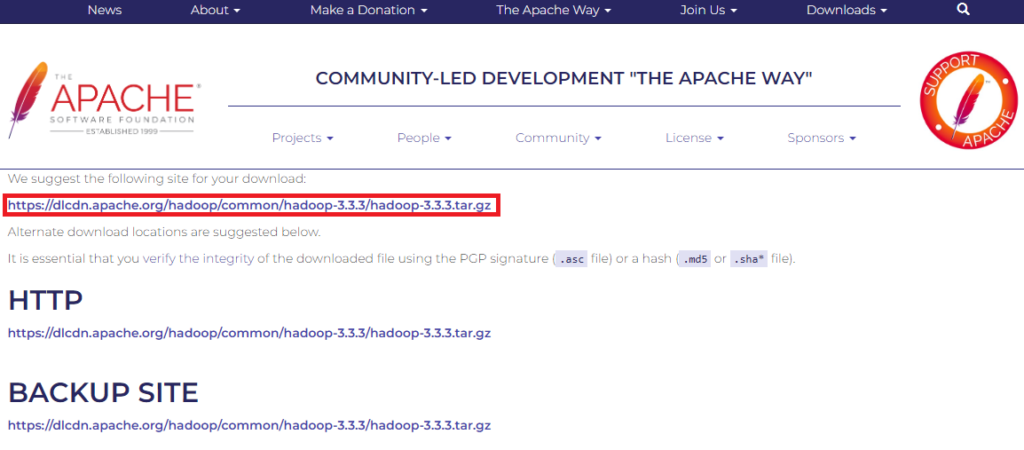
Utilisez le miroir suggéré pour lancer le téléchargement via la commande wget.
Ensuite vous pourrez extraire les fichiers du fichier compressé .tar.gz en utilisant la commande tar. Enfin assurez vous que le répertoire « hadoop-3.3.2 » est positionné dans /usr/local. Les commandes suivantes vous permettent de réaliser ces opérations:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.3/hadoop-3.3.3.tar.gz
tar -xvf hadoop-3.3.2.tar.gz
mv hadoop-3.3.2 /usr/local/Ajouter les variables d’environnement pour Hadoop
Des variables d’environnements ont besoin d’être ajouté au fichier .bashrc pour définir les répertoires d’Hadoop. Ouvrez le fichier .bashrc dans un éditeur de texte et ajoutez les lignes suivantes:
# Variables Hadoop
export HADOOP_HOME=/usr/local/hadoop-3.3.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"Tapez la commande la commande « source .basrc » dans un terminal pour recharger ces nouvelles variables d’environnement. Enfin vérifiez que la variable $HADOOP_HOME renvoie le chemin du répertoire où Hadoop a été positionné avec la commande « echo »:
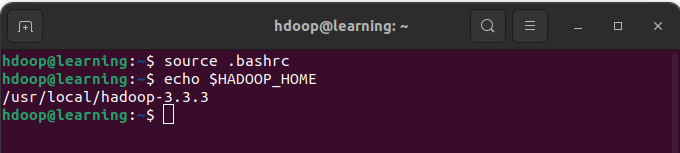
Modifier les variables d’environnement d’Hadoop
Nous allons modifier la variable JAVA_HOME pour indiquer à Hadoop quelle version de java installée est à utiliser. En l’occurence ici, il s’agit de Java 8 conformément au prérequis. Ouvrez le fichier $HADOOP_HOME/etc//hadoop/hadoop-env.sh pour modifier la variable JAVA_HOME comme ceci:
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/A présent en tapant dans un terminal la commande « hadoop version« , vous devez avoir un message du type:
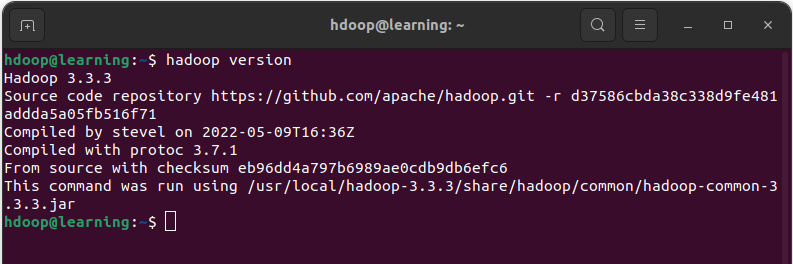
Configurer les composants de Hadoop
La configuration de chacun des composants de Hadoop est définie à partir de fichiers XML. Les propriétés communes de votre installation Hadoop sont faites dans le fichier core-site.xml. Et les différents composants HDFS, MapReduce et YARN sont paramétrés respectivement dans les fichiers hdfs-site.xml, mapred-site.xml et yarn-site.xml. L’ensemble de ces fichiers se trouvent dans le répertoire de votre installation $HADOOP_HOME/etc/hadoop. Pour chacun de ces fichiers, nous allons voir les paramètres qu’il est nécessaire de renseigner.
Hadoop Core
Ouvrez le fichier core-site.xml pour modifier les deux variables:
- hadoop.tmp.dir: répertoire contenant tout les fichiers de travail de Hadoop,
- fs.defaultFS: nom du système de fichier.
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdoop/tmpdata</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>HDFS
Ouvrez le fichier hdfs-site.xml pour modifier les variables suivantes:
- dfs.namenode.name.dir: répertoire de stockage des données du namenode,
- dfs.datanode.data.dir: répertoire de stockage des données du datanode,
- dfs.replication: nombre de réplication d’un bloc. Une valeur de 1 car notre cluster est composé d’un seul nœud.
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hdoop/dfsdata/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hdoop/dfsdata/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>MapReduce
Ouvrez le fichier mapred-site.xml pour modifier les paramètres suivants:
- mapreduce.framework.name: indique que Yarn est utilisé pour l’implémentation de MapReduce,
- mapreduce.application.classpath: spécifie les répertoires contenant les archives du composant MapReduce.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/usr/local/hadoop-3.3.3/etc/hadoop:/usr/local/hadoop-3.3.3/share/hadoop/common/lib/*:/usr/local/hadoop-3.3.3/share/hadoop/common/*:/usr/local/hadoop-3.3.3/share/hadoop/hdfs:/usr/local/hadoop-3.3.3/share/hadoop/hdfs/lib/*:/usr/local/hadoop-3.3.3/share/hadoop/hdfs/*:/usr/local/hadoop-3.3.3/share/hadoop/mapreduce/*:/usr/local/hadoop-3.3.3/share/hadoop/yarn:/usr/local/hadoop-3.3.3/share/hadoop/yarn/lib/*:/usr/local/hadoop-3.3.3/share/hadoop/yarn/*</value>
</property>
</configuration>YARN
Ouvrez le fichier yarn-site.xml pour modifier les paramètres suivants:
- yarn.nodemanager.aux-services: nom du service utilisé par Yarn,
- yarn.nodemanager.env-whitelist: ensemble de variables d’environnements.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,
CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>Initialiser HDFS
Avant de lancer votre serveur Hadoop, vous devez formater le système de fichier HDFS. Toujours en utilisant l’utilisateur hdoop, exécutez dans un terminal la commande suivante:
hdfs namenode -formatDémarrer le serveur Hadoop
A présent, vous allez pouvoir démarrer votre serveur Hadoop en deux étapes.
- Pour démarrer le namenode et le datanode, vous devez lancer le démon HDFS avec la commande:
start-dfs.sh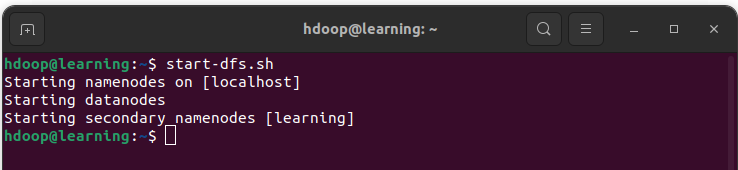
- Pour démarrer YARN et le NodeManagers, vous devez lancer le démon YARN avec la commande:
start-yarn.sh
Afin de vous assurer que tous les démons sont actifs et s’exécutent en tant que processus Java, exécutez la commande « jps » dans un terminal. Cette commande doit vous retourner des messages similaires à:
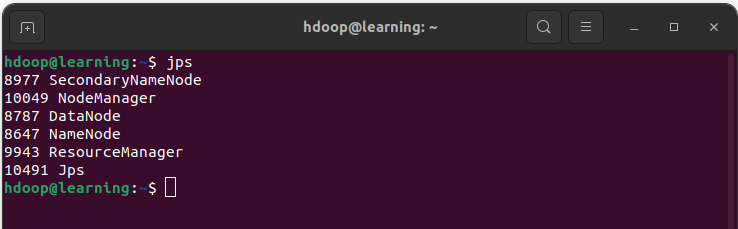
Tester l’installation
Une fois l’ensemble des démons démarrés, il est également possible de vérifier leur bon fonctionnement via trois interfaces utilisateurs incluses dans l’installation d’Hadoop:
- Hadoop NameNode: http://localhost:9870
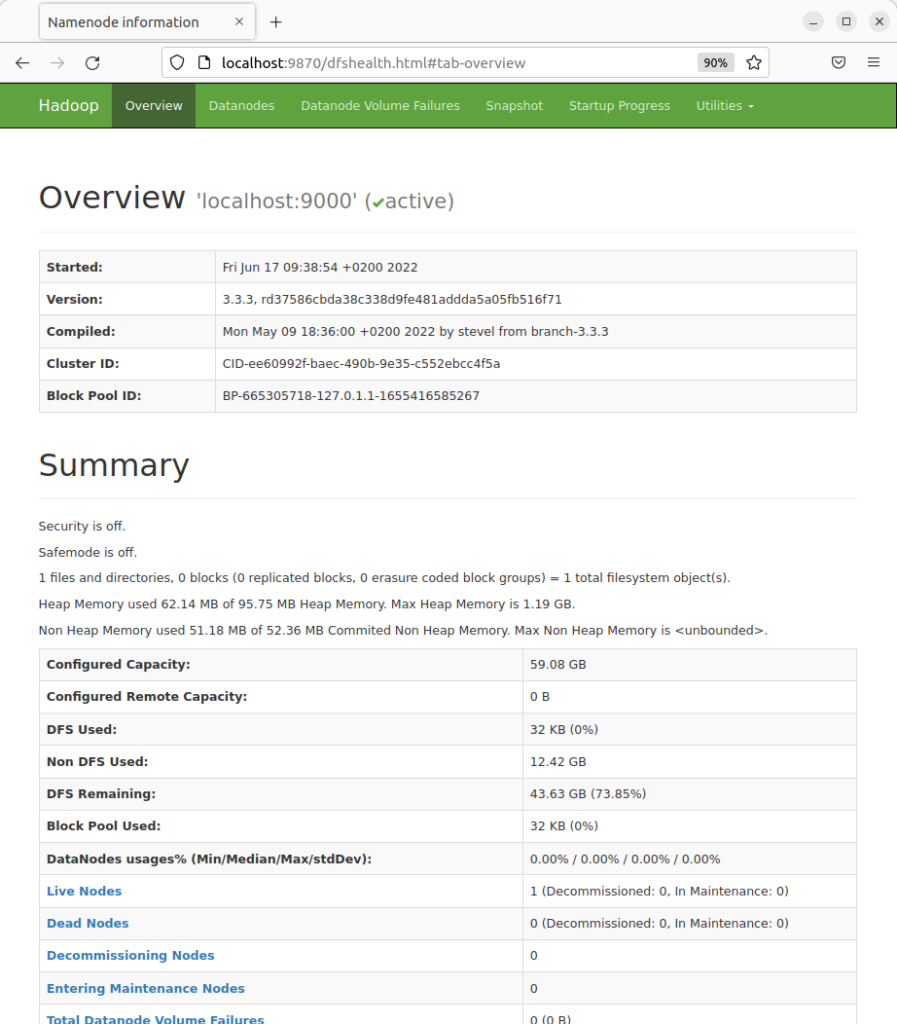
- Individual DataNodes: http://localhost:9864
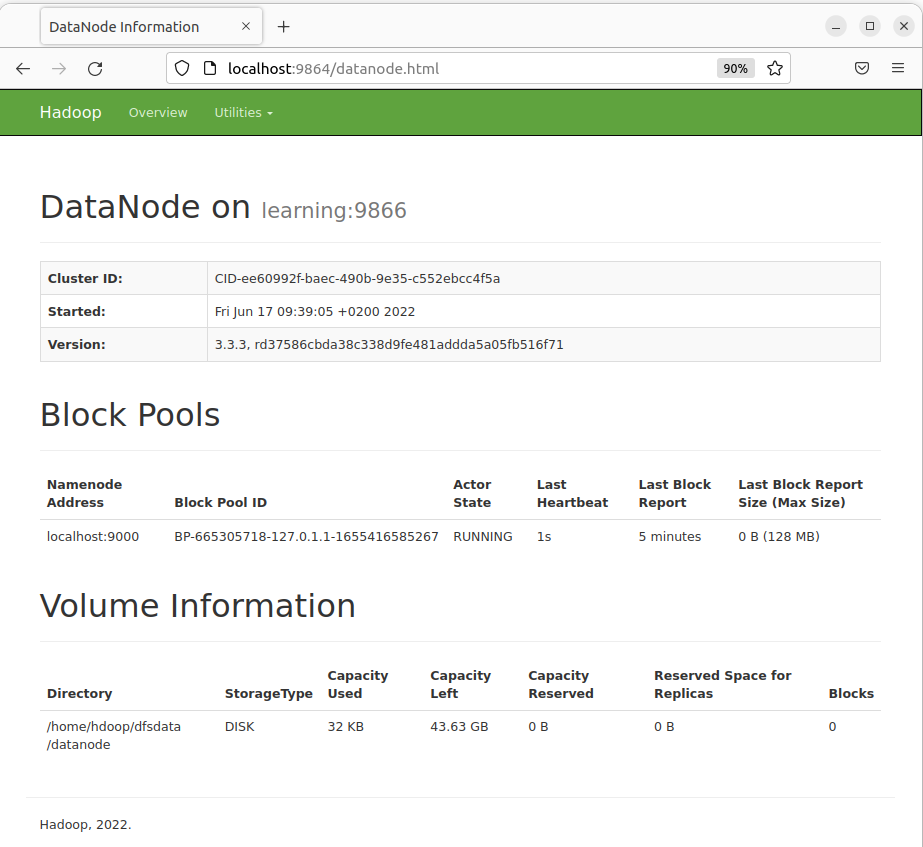
- YARN ResourceManager: http://localhost:8088

Arrêter le serveur Hadoop
L’arrêt du serveur Hadoop se fait par des commandes spécifiques comme pour le démarrage du serveur.
- Arrêtez les démons HDFS avec la commande suivante:
stop-dfs.sh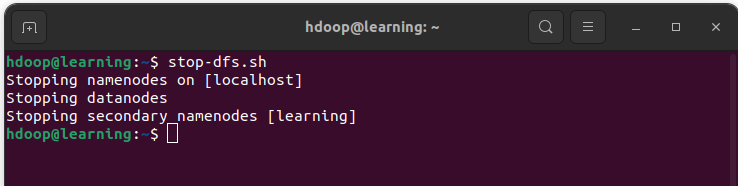
- Arrêtez les démons YARN avec la commande suivante:
stop-yarn.sh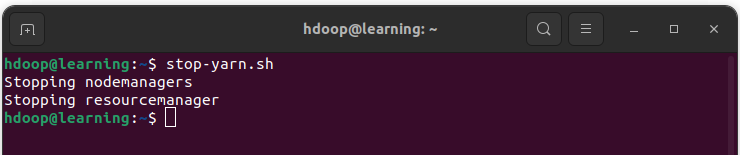
Conclusion
Félicitations, vous avez maintenant une installation complète et opérationnelle de Apache Hadoop. Vous pouvez commencer à tester vos développements dans l’écosystème Hadoop.
Pour aller plus loin, vous pouvez consulter nos articles:
Référence
Les références ayant servi à la rédaction de cet article: