
Cet article va vous présenter comment écrire un programme MapReduce Hadoop en utilisant le langage de programmation Python.
Hadoop est développé en Java et permet d’écrire des programmes map/reduce en Java. Mais il est tout à fait possible d’écrire des applications MapReduce dans d’autres langages en utilisant l’API Hadoop Streaming. Cette API prend en charge tous les langages qui peuvent lire à partir de l’entrée standard et écrire sur la sortie standard.
Prérequis
Il est nécessaire d’avoir une installation d’Apache Hadoop. Si besoin , vous pouvez consulter notre article sur comment installer Hadoop sur une machine Ubuntu. Pour pouvoir reproduire l’exemple présenté, pensez à démarrer votre serveur HDFS et Yarn.
Nous allons également devoir manipuler des fichiers sur le serveur HDFS. Les commandes à exécuter seront données. Toutefois, vous pouvez consulter l’article Manipuler vos fichiers sur HDFS en ligne de commandes pour en savoir plus.
Nous allons utiliser des scripts python exécutables pour définir le mapper et le reducer. Vous devrez renseigner en tête de chaque script Python le chemin vers l’interpréteur python de la forme: #!/usr/bin/python3 (à personnaliser suivant l’interpréteur Python que vous souhaitez utiliser).
Description du problème à résoudre
Nous allons reprendre le problème classique de comptage du nombre d’occurrences des mots dans des fichiers textes. Le programme reçoit en entrée des fichiers textes. L’étape du map permet d’associer à chaque terme le nombre 1. En sortie de l’étape de reduce, un fichier texte est produit et contiendra sur chaque ligne un mot et le nombre d’occurrences de ce mot séparé par une tabulation.
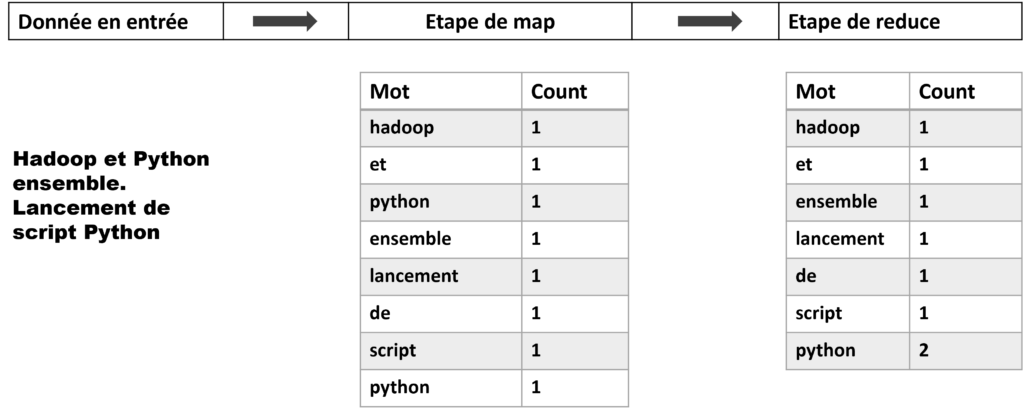
Programme MapReduce écrit en Python
Nous allons présenter les deux scripts qui vont servir de mapper et de reducer pour l’application MapReduce que nous cherchons à mettre en place. Les deux scripts seront sauvegardés dans /home/hdoop/Documents/hadoop-stremaing/
Etape de Map
Copiez et sauvegardez ce code dans un script mapper.py. Ce script lit à partir de l’entrée standard STDIN (commande sys.stdin) les données. Chaque ligne va être divisée en mot et retournée sous forme de tuple sur la sortie standard STDOUT. Chaque tuple sera de la forme « <mot> 1 ». Il s’agit évidemment d’un comptage intermédiaire étant donné qu’un mot peut être répété plus d’une fois. Le comptage final par mot sera calculé par le reducer dans l’étape suivante.
#!/usr/bin/python3.10
import re
import sys
for line in sys.stdin:
# suppression des espaces en début et fin de ligne
line = line.strip()
# suppression de la ponctuation et mise en minuscule
line = re.sub(r"[^\w\s]", ' ', line.lower())
# division des lignes en mots
words = line.split()
for word in words:
# écriture des résultats en STDOUT avec des tabulations en délimiteur
print(f"{word.lower()} \t 1")Etape de Reduce
Copiez et sauvegardez ce code dans un script reducer.py. Ce script lit à partir de l’entrée standard STDIN les sorties du script mapper.py. Les occurrences de chaque mot sont agrégées et écrites sur la sortie standard STDOUT.
#!/usr/bin/python3
import sys
current_word = None
current_count = 0
word = None
# lecture depuis l'entrée standard STDIN
for line in sys.stdin:
# suppression des espaces en début et fin de ligne
line = line.strip()
# divise une chaîne de caractère issus du mapper.py
# en une liste sur la tabulation
word, count = line.split('\t', 1)
# convertit la variable count en entier (string initialement)
try:
count = int(count)
except ValueError:
# si count n'est pas un nombre, on ignore la ligne
continue
# trie la sortie de mapperpy par Hadoop par mot
# avant d'être traité par le reducer
if current_word == word:
current_count += count
else:
if current_word:
# écriture du résultat sur la sortie standard STDOUT
print(f"{current_word}\t{current_count}")
current_count = count
current_word = word
# écriture du résultat du dernier mot sur la sortie
# standard STDOUT si besoin
if current_word == word:
print(f"{current_word}\t{current_count}")Tester son code en local
Avant d’utiliser Hadoop Streaming, il est conseillé tester ces deux scripts Python. Au préalable, il faut changer les permissions de ces deux fichiers en donnant à l’utilisateur l’autorisation de les exécuter:
chmod u+x mapper.py
chmod u+x reducer.pyNous allons commencer par tester le mapper en utilisant une phrase simple de test: « Hadoop et Python ensemble. Lancement de scripts Python ». Entrez la commande suivante dans un terminal:
echo "Hadoop et Python ensemble. Lancement Script Python" | ./mapper.py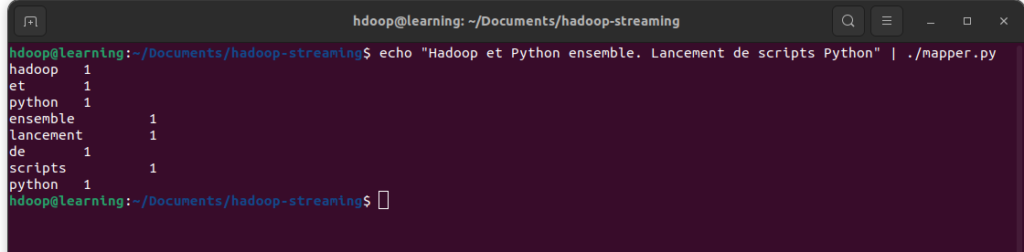
On retrouve le résultat attendu: chaque mot est associé à la valeur 1. Le mot « Python » étant répété deux fois dans la phrase de test et il apparaît donc deux fois dans le résultat sous la forme: « python 1 ».
Enfin pour reproduire le comportement de Hadoop en streaming, nous pouvons tester le processus de MapReduce avec la commande suivante:
echo "Hadoop et Python ensemble. Lancement Script Python" | ./mapper.py | sort -k1,1 | ./reducer.py
On retrouve dans ce cas pour chaque mot, son nombre d’occurrence dans la phrase simple qui a été testée. Le mot « Python » apparaît dans le résultat final sour la forme « python 2 » car il apparaît deux fois.
Exécuter un job Streaming MapReduce
Dans cette section, nous allons décrire les étapes pour exécuter un exemple complet en utilisant Hadoop Streaming.
Télécharger les données d’entrée
Pour réaliser un test plus complet, nous proposons d’utiliser des livres mis à disposition gratuitement par le projet Gutenberg:
- Les misérables Tome 1: Fantine par Victor Hugo
- Les misérables Tome 2: Cosette par Victor Hugo
- Les misérables Tome 3: Marius par Victor Hugo
Utilisez chaque lien pour télécharger la version texte au format Plain Text UTF-8.
Copier les données d’entrée sur HDFS
Les données à traiter avec Hadoop Streaming doivent être placé sur HDFS. Pour cela, vous devez les copier depuis votre local sur HDFS en utilisant la commande « hdfs dfs -copyFromLocal » de la façon suivante:

Dans cet exemple, les répertoires sont définis comme :
- en local: « /home/hdoop/Documents/data/gutenberg« . Répertoire dans lequel les fichiers du projet Gutenberg ont été sauvegardés.
- sur HDFS: « /user/hdoop/gutenberg« . Répertoire sur HDFS dans lequel les fichiers sont copiés.
Exécuter le processus avec Hadoop MapReduce
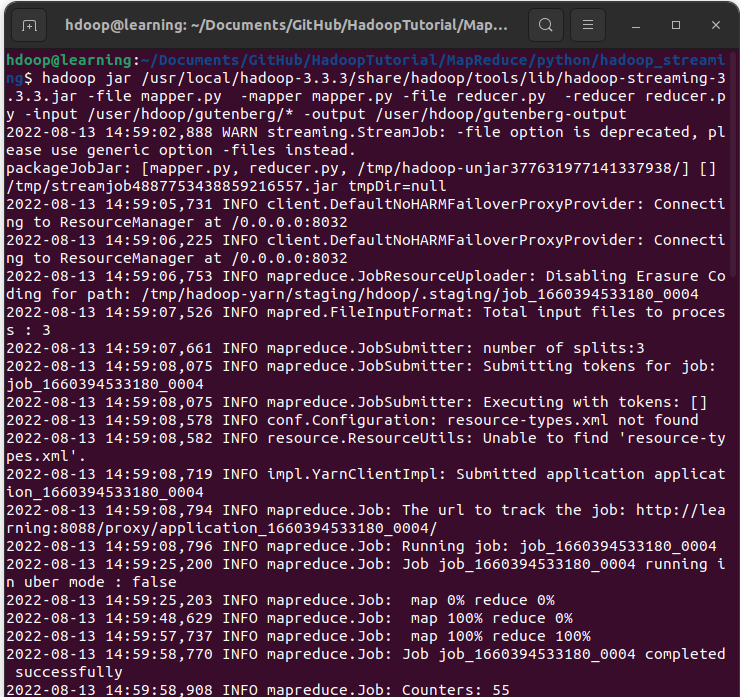
Depuis le répertoire dans lequel vous avez sauvegardé les scripts mapper.py et reducer.py, nous allons lancer la commande Hadoop pour exécuter ce job en streaming MapReduce. Dans un terminal, tapez la commande suivante:
hadoop jar /usr/local/hadoop-3.3.3/share/hadoop/tools/lib/hadoop-streaming-3.3.3.jar \
-file mapper.py -mapper mapper.py \
-file reducer.py -reducer reducer.py \
-input /user/hdoop/gutenberg/* \
-output /user/hdoop/gutenberg-outputVous pouvez voir ici que nous avons utilisé le jar hadoop-streaming-3.3.3 qui correspond à celui de la version d’Hadoop 3.3.3. Modifiez-le en fonction de la version de Hadoop installée sur votre machine si différente.
Les options de bases utilisées pour cette commande sont les suivantes:
| Option | Description |
|---|---|
| -mapper | commande à exécuter pour le map |
| -reducer | commande à exécuter pour le reduce |
| -input | le path sur HDFS contenant les données d’entrée du mapper |
| -output | le path HDFS pour l’écriture des résultats du reducer |
| -file | chemin des exécutables en local mis à disposition des nœuds de calculs |
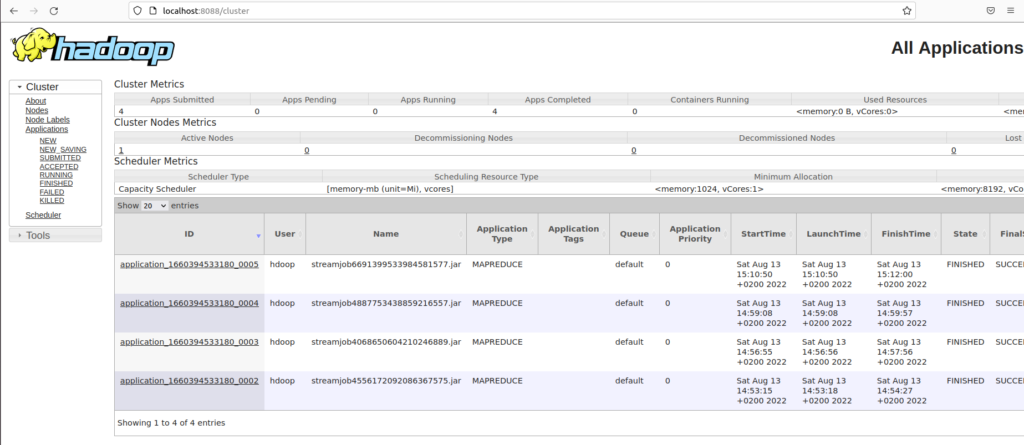
Une fois le processus Hadoop lancé, il est possible de le monitorer depuis l’interface http://localhost:8088/. Elle donne plusieurs informations comme le détail des processus en cours, terminé en succès ou en échec et un ensemble d’information utile pour monitorer vos calculs.
Conclusion
Félicitations, vous avez dorénavant les connaissances nécessaire pour développer vos programmes MapReduce en Python. Et vous savez comment comment les exécuter en utilisant l’API Hadoop Streaming.
Sur le même sujet: Consulter l’article Installer Hadoop sur Ubuntu
Pour aller plus loin: Consulter l’article Requêter avec HiveQL
Référence
Les références ayant servi à la rédaction de cet article: