
Ce tutoriel présente les commandes pour manipuler des fichiers sur HDFS (Hadoop Distributed File System).
Deux options sont possibles pour gérer vos données sur HDFS: avec l’API Java ou alors en ligne de commande Hadoop. C’est cette deuxième option qui est présentée dans ce tutoriel.
Prérequis
Vous devez avoir au préalable installé Apache Hadoop. En cas de besoin, un tutoriel sur comment Installer Hadoop sur Ubuntu est disponible sur ce site. Assurez vous d’avoir lancé votre serveur Hadoop comme cela est décrit dans cet article.
Récupération des données MovieLens
Dans cet article, nous proposons d’utiliser un jeu de données mis à disposition par le laboratoire MovieLens. Il s’agit de jeu de données public classiquement utilisé pour les démonstrations des moteurs de recommandations. Vous pouvez télécharger les données MovieLens 100K Dataset depuis le site officiel ou bien depuis notre page GitHub.
Après avoir téléchargé ces données, décompressez les sur le local de la session sur lequel vous avez accès au système de fichiers HDFS.
Structure générale des commandes HDFS
Les commandes HDFS sont très similaires aux commandes UNIX. Ainsi, les utilisateurs de machine Linux verront immédiatement les similarités avec les commandes qu’ils utilisent habituellement. L’ensemble des commandes HDFS se présente sous la forme suivante:
hdfs dfs <commande> [option] <args>
L’expression <commande> sont des commandes de type UNIX dont nous allons donner des exemples ci-dessous. [option] permet de spécifier des options de la commande. Enfin <args> sont les arguments donnés par l’utilisateur.
Ces commandes Shell vont vous permettre d’interagir directement avec les fichiers stockés sur HDFS depuis un terminal. La liste complète des commandes est disponible sur la documentation Hadoop.
Commande shell pour HDFS
Voici la liste des commandes que nous allons voir ensemble:
- Lister le contenu d’un répertoire
- Créer un répertoire
- Afficher le contenu d’un fichier
- Charger un fichier sur HDFS
- Récupérer un fichier depuis HDFS
- Déplacer un fichier
- Copier un fichier
- Supprimer un fichier
- Supprimer un répertoire
Pour chaque commande, nous allons donner la syntaxe générale. Puis nous donnerons des exemples d’utilisation avec les données MovieLens.
Lister le contenu d’un répertoire
La commande ls permet de lister le contenu d’un répertoire.
hdfs dfs -ls <chemin du répertoire>
Exemple: Lister le contenu du dossier
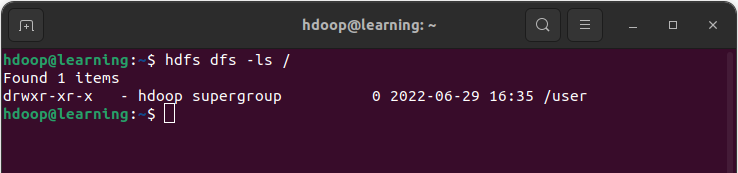
Le répertoire courant contient un seul dossier « /user« . Nous allons utiliser la commande ls dans la suite de cet article pour montrer les résultats des commandes qui sont présentés.
Créer un répertoire
La commande mkdir permet de créer un dossier dans HDFS.
hdfs dfs -mkdir <chemin du nouveau répertoire>
Exemple: Créer le répertoire /user avec la commande mkdir.
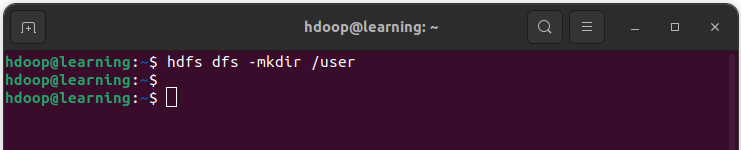
Exemple: Créer les sous-répertoires /hdoop/ml-100k dans /user. L’option -p permet de créer les répertoires parents s’ils n’existent pas.

Afficher le contenu d’un fichier
La commande cat permet d’afficher dans le terminal le contenu d’un fichier. Tandis que la commande tail affiche le dernier kilo bytes d’un fichier.
hdfs dfs -cat <chemin du fichier>
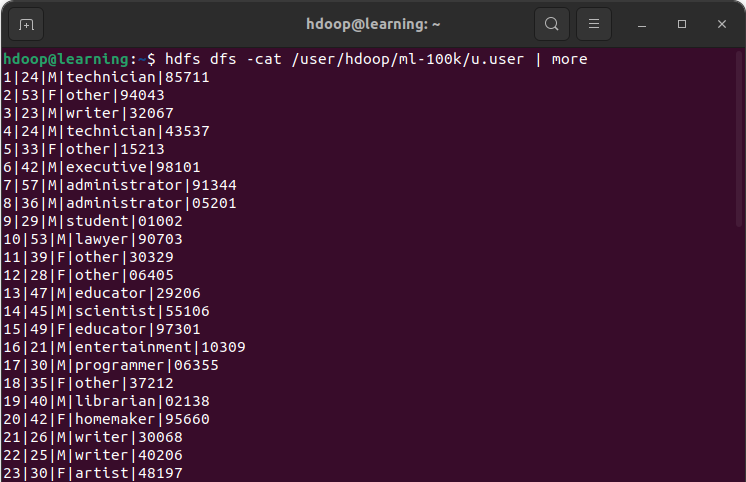
Exemple: Afficher le contenu du fichier « /user/hdoop/ml-100k/u.data » avec la commande cat. L’option | more permet de contrôler le nombre de lignes affichées lorsque le fichier contient un nombre de lignes important.
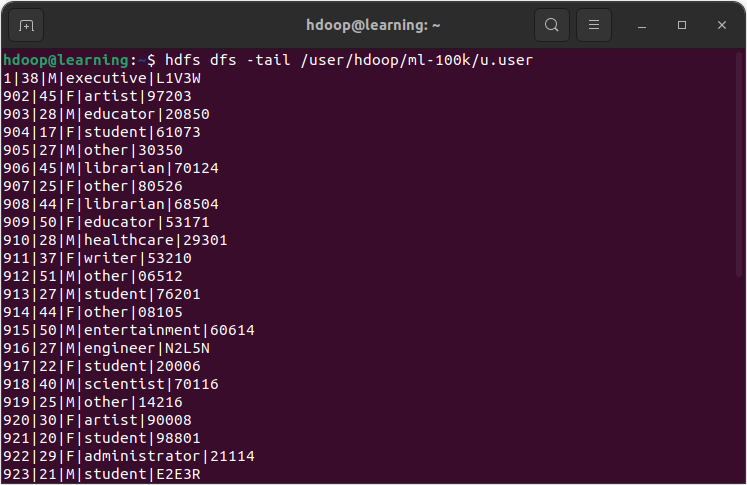
Exemple: Afficher dans le terminal le contenu du fichier « /user/hdoop/ml-100k/u.data » avec la commande tail.
Charger un fichier sur HDFS
Les commandes put et copyFromLocal permettent de charger un ou plusieurs fichiers du local sur HDFS. Les deux commandes sont similaires.
hdfs dfs -put <local src path> <dst path on HDFS>
hadoop fs -copyFromLocal <local src path> <dst path on HDFS>
Exemple: Copier le fichier « u.info » dans /user/hdoop/ml-100k sur HDFS avec la commande put.
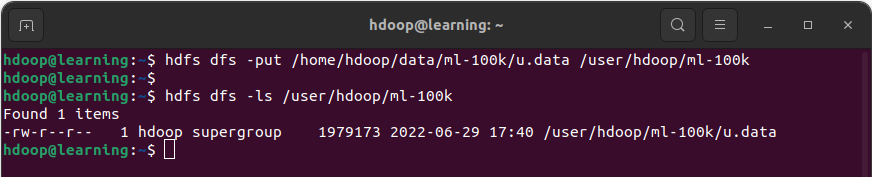
Exemple: Copier les fichiers « u.user » et « u.item » dans /user/hdoop/ml-100K sur HDFS avec la commande copyFromLocal.

Récupérer un fichier depuis HDFS
Les commandes get et copyToLocal permettent de récupérer des fichier HDFS sur votre local. Ces deux commandes fonctionnent de façon similaire.
hdfs dfs -get <HDFS src path> <local dst path>
hadoop fs -copyToLocal <HDFS src path> <local dst path>
Exemple: Copier le fichier « u.data » de HDFS dans un répertoire local (ici /home/hdoop/data/ml-100k_hdfs) avec la commande get.

Exemple: Copier les fichier « u.user » et « u.item » de HDFS dans un répertoire local avec la commande copyToLocal.

Dans ces deux exemples, la commande ls sur votre localhost (ls /home/hdoop/ml-100k_hdfs) permet de retrouver les fichiers récupérés depuis votre système de fichier HDFS.
Déplacer un fichier
La commande mv est utilisée pour déplacer des fichiers sur HDFS.
hdfs dfs -mv <HDFS src path> <HDFS dst path>
Exemple: Commencer par créer un répertoire /user/hdoop/examples en utilisant la commande mkdir. Puis déplacer le fichier « u.data » du dossier /user/hdoop/ml-100k vers /user/hdoop/examples en utilisant la commande mv.
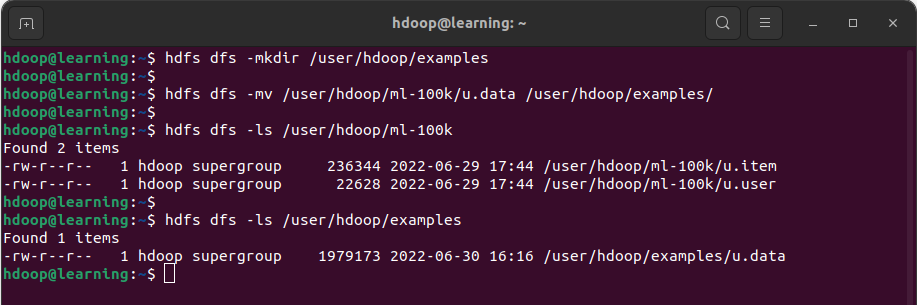
La commande ls sur le répertoire HDFS source (/user/hdoop/ml-100k) montre que le fichier « u.data’ a bien été déplacé. Tandis que la commande ls sur le répertoire HDFS de destination(/user/hdoop/examples) montre que le fichier « u.data’ est présent.
Copier un fichier
La commande cp est utilisée pour copier des fichiers sur HDFS.
hdfs dfs -cp <HDFS src path> <HDFS dst path>
Exemple: Copier le fichier « u.user » du répertoire /user/hdoop/ml-100k vers /user/hdoop/examples
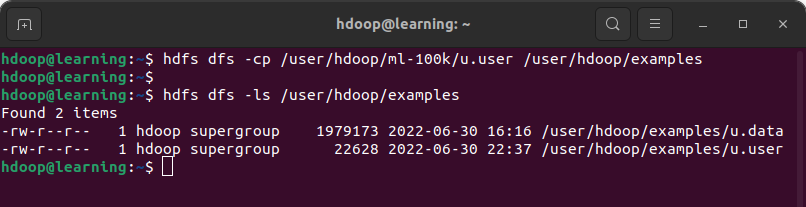
Supprimer un fichier
La commande rm permet de supprimer un fichier dans HDFS.
hdfs dfs -rm <HDFS file path>
Exemple: Supprimer les fichiers conformes au pattern /user/hdoop/example/u.*
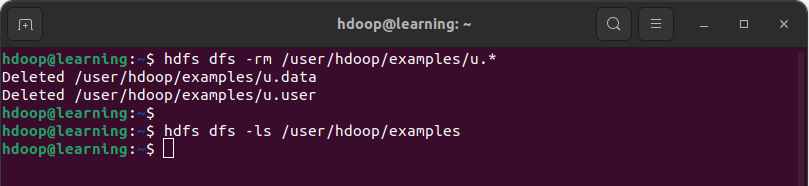
La commande ls permet de confirmer que le répertoire « /user/hdoop/examples » est dorénavant vide.
Supprimer un répertoire
La commande rmdir permet de supprimer un répertoire HDFS vide. Pour supprimer un répertoire non vide de manière récursive, il faut utiliser la commande rm -r.
hdfs dfs -rmdir <empty HDFS dir path>
hdfs dfs -rm -r <non empty HDFS dir path>
Exemple: Supprimer le répertoire vide « /user/hdoop/examples » avec la commande rmdir. Ensuite supprimer le répertoire non vide « /user/hdoop/ml-100k » avec la commande rm -r.
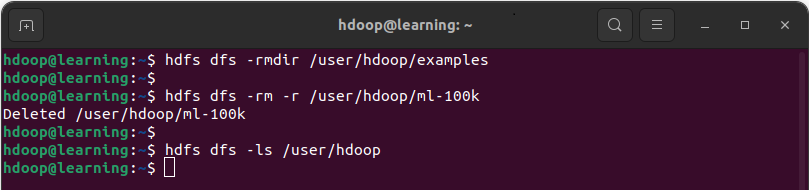
Liste complète des commandes HDFS
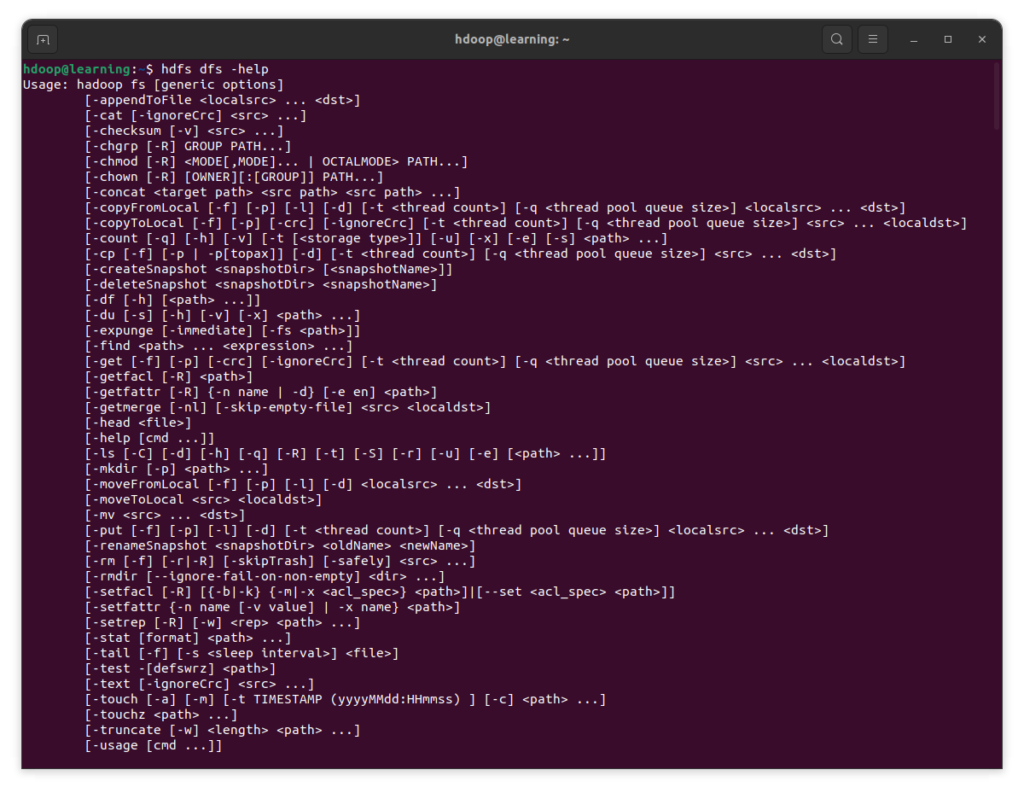
Pour une liste exhaustive des commandes disponibles sur HDFS, tapez la commande « hdfs dfs -help » pour les afficher dans le terminal. Pour chaque commande, les options disponibles sont indiquées.
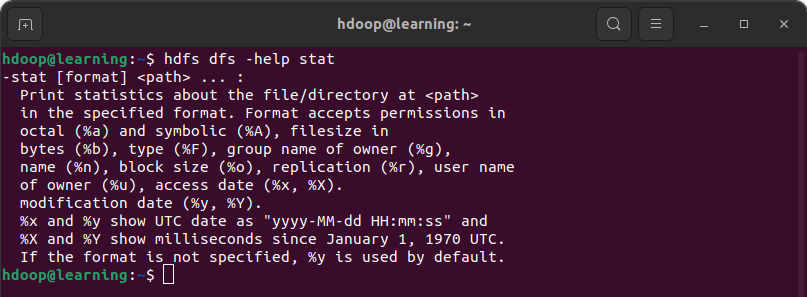
Pour afficher la documentation spécifique d’une commande, il suffit d’ajouter le nom de commande. Par exemple, la documentation de la commande stat s’obtient de la façon suivante:
Interface Utilisateur
Apache Hadoop est fourni avec une interface utilisateur qui permet de visualiser le contenu de votre serveur Hadoop HDFS à la manière d’un explorateur de fichiers. Ouvrez votre navigateur web pour aller sur l’adresse http://localhost:9870. Cliquez sur le Menu « Utilities » puis sur l’onglet « Browse the file system« . Vous arrivez alors sur cette page:
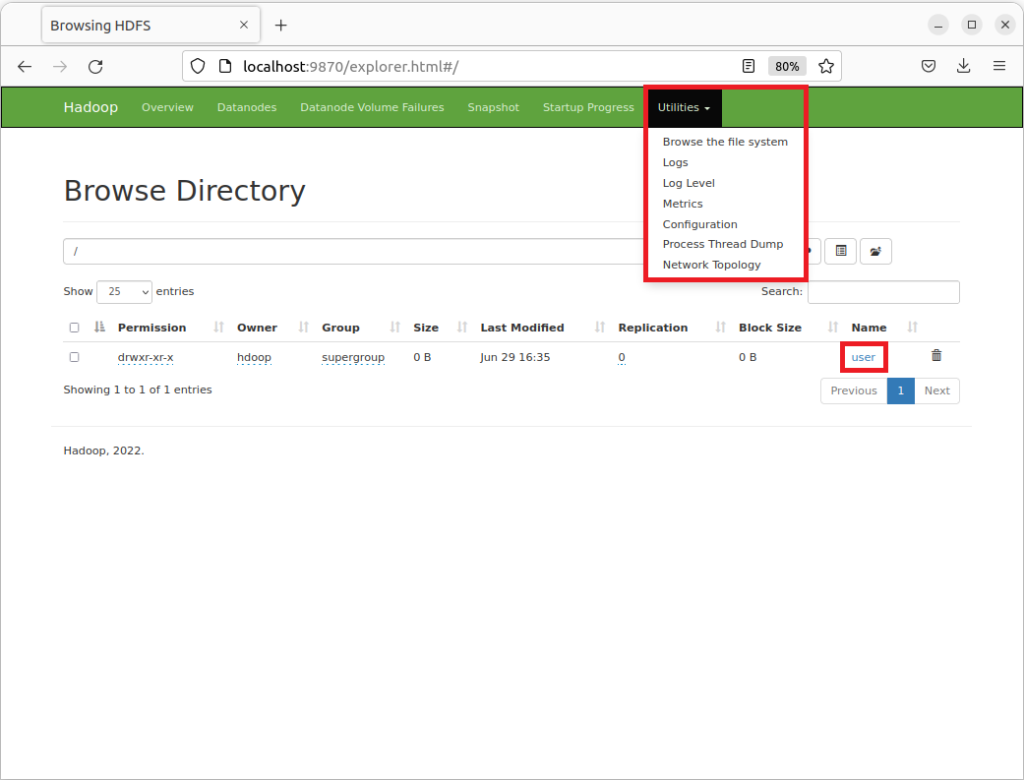
Vous pouvez alors naviguer dans les répertoires de système de fichiers. Sur l’image ci-dessus, vous retrouvez le répertoire « user/« .
En cliquant sur un fichier, un menu propose de télécharger ou bien de visualiser les premières ou dernières lignes du fichier dans l’interface.

Conclusion
Félicitations, vous avez réalisé vos premières manipulations sur HDFS en ligne de commandes.
Sur le même sujet: Consulter l’article Installer Hadoop sur Ubuntu
Pour aller plus loin: Consulter l’article Requêter avec HiveQL
Référence
Les références ayant servi à la rédaction de cet article: