
Pré-requis
Le prérequis à une installation de Hive est une installation complète et fonctionnelle de Hadoop. Assurez vous que l’ensemble des démons d’Hadoop tourne. Vous pouvez consulter notre article sur l’installation complète d’Apache Hadoop pour de plus amples détails.
Télécharger Hive
Vous pouvez télécharger un binaire de Hive depuis le site officiel de Apache Hive.
Pour ce tutoriel, nous allons installer une version stable de Hive. Vous allez donc utiliser le binaire disponible dans le sous répertoire stable-2/.
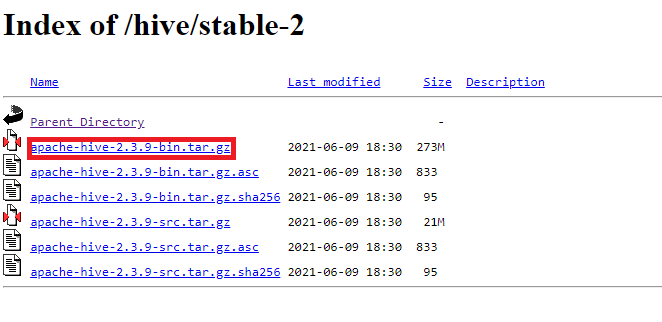
Téléchargez le binaire avec la commande « wget » et décompressez le fichier tar.gz. Enfin placez le répertoire dans /user/local/. Voici les commandes à exécuter dans un terminal pour réaliser ces opérations:
wget https://dlcdn.apache.org/hive/stable-2/apache-hive-2.3.9-bin.tar.gz
tar -xvf apache-hive-2.3.9-bin.tar.gz
sudo mv apache-hive-2.3.9-bin /usr/local/apache-hive-2.3.9Ajouter les variables d’environnement Hive
Hive utilise la variable d’environnement HADOOP_HOME pour situer les fichiers de configuration d’Hadoop et les JAR associés. Cette variable d’environnement doit être obligatoirement renseignée dans le fichier .bashrc (voir le tutoriel Installer Hadoop sur Ubuntu).
De plus, nous allons devoir ajouter une variable d’environnement HIVE_HOME. Ouvrez le fichier .bashrc et renseignez les lignes suivantes:
# Variables Hive
export HIVE_HOME=/usr/local/hive-2.3.9
export PATH=$PATH:$HIVE_HOME/binRechargez les variables d’environnement avec la commande « source .bashrc« . Vous pouvez alors vérifier que la variable d’environnement pointe bien vers le répertoire d’installation de Hive:

Configurer les composants Hive
Hive a besoin d’avoir accès à HDFS (Hadoop Distributed File System). Pour cela, ouvrez le fichier de configuration Hive « $HIVE_HOME/bin/hive-config.sh » et ajoutez la variable HADOOP_HOME avec le chemin d’installation de Hadoop sur votre machine.
export HADOOP_HOME=/usr/local/hadoop-3.3.3Créer les répertoires Hive sur HDFS
Nous allons créer l’entrepôt des données Hive sur HDFS. Ouvrez un terminal pour créer le répertoire « /user/hive/warehouse » sur HDFS avec la commande:
hdfs dfs -p /user/hive/warehouseModifiez les droits d’écriture et d’exécution sur ce dépôt avec la commande suivante:
hdfs dfs -chmod g+w /user/hive/warehouseVous pouvez vérifier que le dépôt a été créé avec les permissions souhaitées de la façon suivante:

Initialiser la base de données Derby
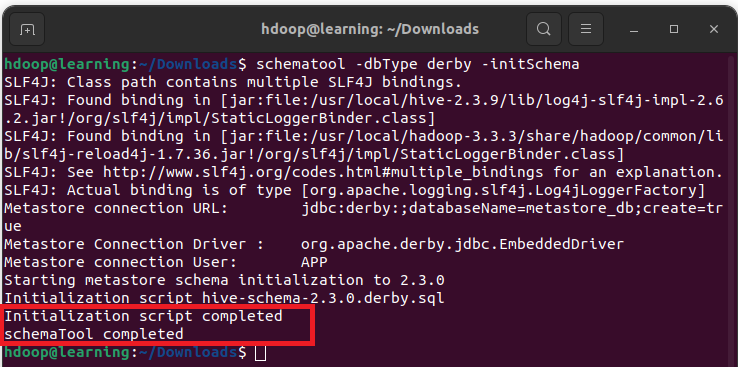
Hive utilise une base de données Derby pour stocker les métadonnées. Dans un terminal, initialisez la base de données Derby avec la commande:
schematool -dbType derby -initSchemaUne fois cette initialisation terminée avec succès, vous devriez avoir un message du type:
Lancer le client shell Hive
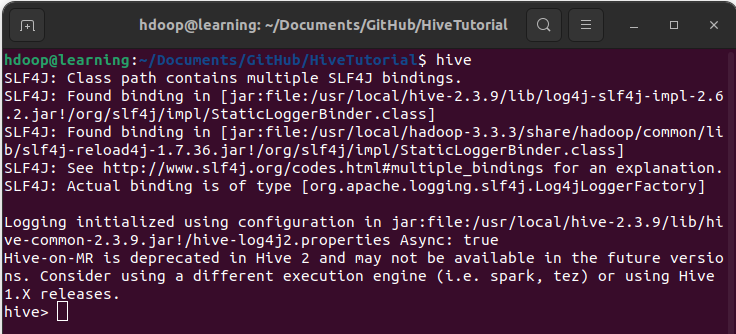
Vous pouvez à présent lancer Hive en ligne de commande. Dans un terminal, tapez « hive« :
Conclusion
Vous disposez à présent d’une installation d’Apache Hive opérationnelle. Vous pouvez interagir avec vos données sur HDFS en utilisant le langage HiveQL de façon similaire avec le langage SQL avec les bases de données relationnelles.
Référence
Les références ayant servi à la rédaction de cet article: