Le prérequis à une installation de Hive est une installation complète et fonctionnelle de Hadoop. Assurez vous que l’ensemble des démons d’Hadoop tourne. Vous pouvez consulter notre article sur l’installation complète d’Apache Hadoop pour de plus amples détails.
Télécharger Hive
Vous pouvez télécharger un binaire de Hive depuis le site officiel de Apache Hive.
Page de téléchargement sur le site officiel d’Apache Hive
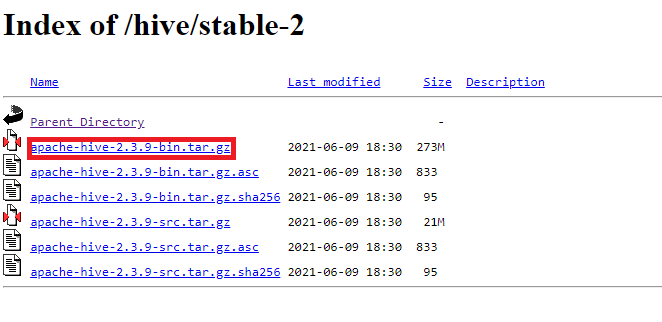
Pour ce tutoriel, nous allons installer une version stable de Hive. Vous allez donc utiliser le binaire disponible dans le sous répertoire stable-2/.
Binaire d’Apache Hive dans une version stable
Téléchargez le binaire avec la commande « wget » et décompressez le fichier tar.gz. Enfin placez le répertoire dans /user/local/. Voici les commandes à exécuter dans un terminal pour réaliser ces opérations:
wget https://dlcdn.apache.org/hive/stable-2/apache-hive-2.3.9-bin.tar.gz
tar -xvf apache-hive-2.3.9-bin.tar.gz
sudo mv apache-hive-2.3.9-bin /usr/local/apache-hive-2.3.9
Ajouter les variables d’environnement Hive
Hive utilise la variable d’environnement HADOOP_HOME pour situer les fichiers de configuration d’Hadoop et les JAR associés. Cette variable d’environnement doit être obligatoirement renseignée dans le fichier .bashrc (voir le tutoriel Installer Hadoop sur Ubuntu).
De plus, nous allons devoir ajouter une variable d’environnement HIVE_HOME. Ouvrez le fichier .bashrc et renseignez les lignes suivantes:
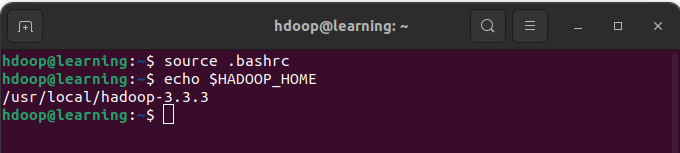
Rechargez les variables d’environnement avec la commande « source .bashrc« . Vous pouvez alors vérifier que la variable d’environnement pointe bien vers le répertoire d’installation de Hive:
Source du fichier .bashrc et affichage de la variable d’environnement $HIVE_HOME
Configurer les composants Hive
Hive a besoin d’avoir accès à HDFS (Hadoop Distributed File System). Pour cela, ouvrez le fichier de configuration Hive « $HIVE_HOME/bin/hive-config.sh » et ajoutez la variable HADOOP_HOME avec le chemin d’installation de Hadoop sur votre machine.
export HADOOP_HOME=/usr/local/hadoop-3.3.3
Créer les répertoires Hive sur HDFS
Nous allons créer l’entrepôt des données Hive sur HDFS. Ouvrez un terminal pour créer le répertoire « /user/hive/warehouse » sur HDFS avec la commande:
hdfs dfs -p /user/hive/warehouse
Modifiez les droits d’écriture et d’exécution sur ce dépôt avec la commande suivante:
hdfs dfs -chmod g+w /user/hive/warehouse
Vous pouvez vérifier que le dépôt a été créé avec les permissions souhaitées de la façon suivante:
Permissions d’écriture et d’exécution sur le dépôt Hive: /user/hive/warehouse/
Initialiser la base de données Derby
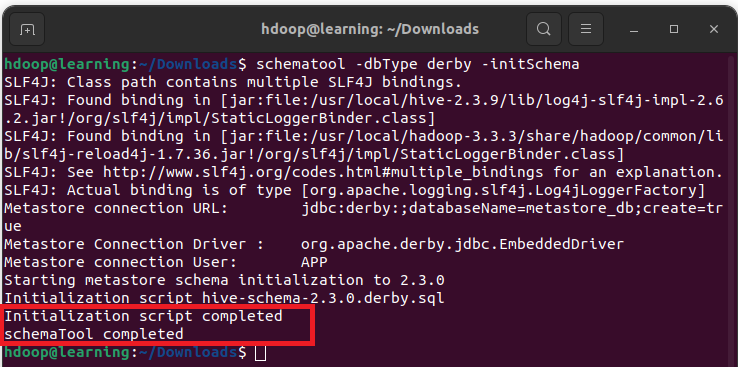
Hive utilise une base de données Derby pour stocker les métadonnées. Dans un terminal, initialisez la base de données Derby avec la commande:
schematool -dbType derby -initSchema
Une fois cette initialisation terminée avec succès, vous devriez avoir un message du type:
Initialisation de la base de donnée Derby pour le stockage des métadonnées Hive
Lancer le client shell Hive
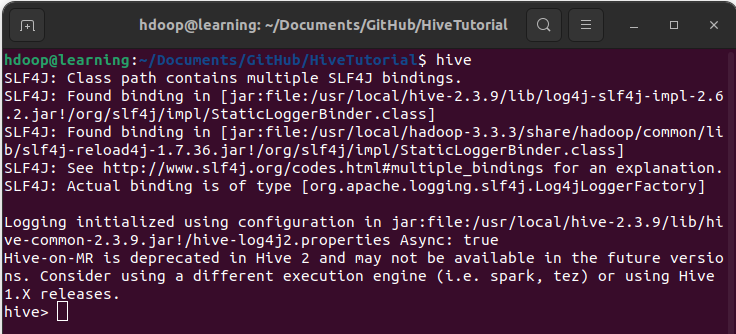
Vous pouvez à présent lancer Hive en ligne de commande. Dans un terminal, tapez « hive« :
Commande « hive » pour lancer Hive en ligne de commande
Conclusion
Vous disposez à présent d’une installation d’Apache Hive opérationnelle. Vous pouvez interagir avec vos données sur HDFS en utilisant le langage HiveQL de façon similaire avec le langage SQL avec les bases de données relationnelles.
Référence
Les références ayant servi à la rédaction de cet article:
Ce tutoriel présente les commandes pour manipuler des fichiers sur HDFS (Hadoop Distributed File System).
Deux options sont possibles pour gérer vos données sur HDFS: avec l’API Java ou alors en ligne de commande Hadoop. C’est cette deuxième option qui est présentée dans ce tutoriel.
Prérequis
Vous devez avoir au préalable installé Apache Hadoop. En cas de besoin, un tutoriel sur comment Installer Hadoop sur Ubuntu est disponible sur ce site. Assurez vous d’avoir lancé votre serveur Hadoop comme cela est décrit dans cet article.
Récupération des données MovieLens
Dans cet article, nous proposons d’utiliser un jeu de données mis à disposition par le laboratoire MovieLens. Il s’agit de jeu de données public classiquement utilisé pour les démonstrations des moteurs de recommandations. Vous pouvez télécharger les données MovieLens 100K Dataset depuis le site officiel ou bien depuis notre page GitHub.
Après avoir téléchargé ces données, décompressez les sur le local de la session sur lequel vous avez accès au système de fichiers HDFS.
Structure générale des commandes HDFS
Les commandes HDFS sont très similaires aux commandes UNIX. Ainsi, les utilisateurs de machine Linux verront immédiatement les similarités avec les commandes qu’ils utilisent habituellement. L’ensemble des commandes HDFS se présente sous la forme suivante:
hdfs dfs <commande> [option] <args>
L’expression <commande> sont des commandes de type UNIX dont nous allons donner des exemples ci-dessous. [option] permet de spécifier des options de la commande. Enfin <args> sont les arguments donnés par l’utilisateur.
Ces commandes Shell vont vous permettre d’interagir directement avec les fichiers stockés sur HDFS depuis un terminal. La liste complète des commandes est disponible sur la documentation Hadoop.
Commande shell pour HDFS
Voici la liste des commandes que nous allons voir ensemble:
Lister le contenu d’un répertoire
Créer un répertoire
Afficher le contenu d’un fichier
Charger un fichier sur HDFS
Récupérer un fichier depuis HDFS
Déplacer un fichier
Copier un fichier
Supprimer un fichier
Supprimer un répertoire
Pour chaque commande, nous allons donner la syntaxe générale. Puis nous donnerons des exemples d’utilisation avec les données MovieLens.
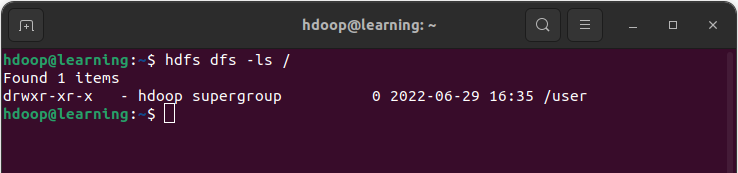
Lister le contenu d’un répertoire
La commande ls permet de lister le contenu d’un répertoire.
hdfs dfs -ls <chemin du répertoire>
Exemple: Lister le contenu du dossier
Liste le contenu d’un dossier HDFS
Le répertoire courant contient un seul dossier « /user« . Nous allons utiliser la commande ls dans la suite de cet article pour montrer les résultats des commandes qui sont présentés.
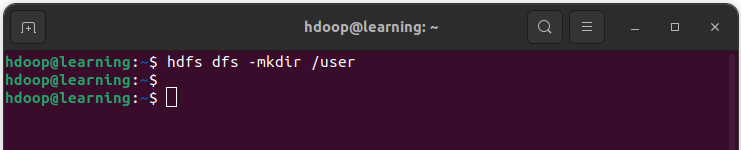
Créer un répertoire
La commande mkdir permet de créer un dossier dans HDFS.
hdfs dfs -mkdir <chemin du nouveau répertoire>
Exemple: Créer le répertoire /user avec la commande mkdir.
Commande pour créer un répertoire sur HDFS
Exemple: Créer les sous-répertoires /hdoop/ml-100k dans /user. L’option -p permet de créer les répertoires parents s’ils n’existent pas.
Commande pour créer un répertoire de manière récursive sur HDFS
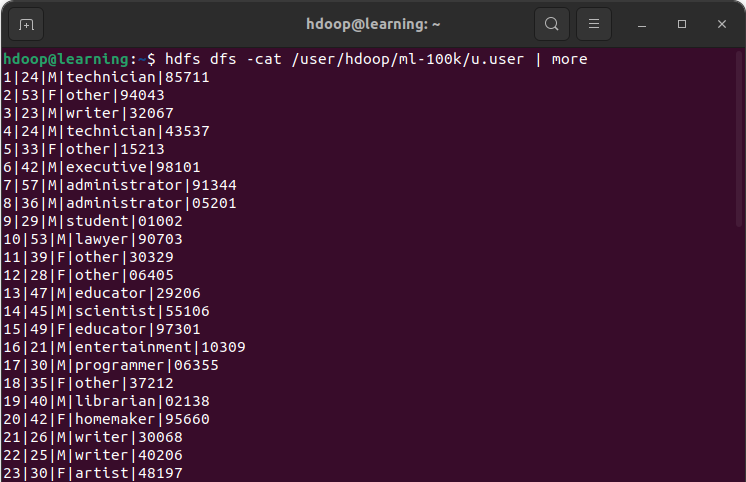
Afficher le contenu d’un fichier
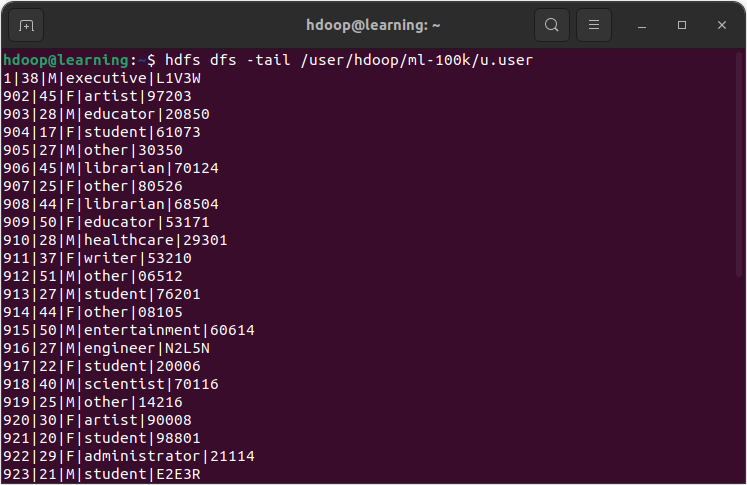
La commande cat permet d’afficher dans le terminal le contenu d’un fichier. Tandis que la commande tail affiche le dernier kilo bytes d’un fichier.
hdfs dfs -cat <chemin du fichier>
Exemple: Afficher le contenu du fichier « /user/hdoop/ml-100k/u.data » avec la commande cat. L’option | more permet de contrôler le nombre de lignes affichées lorsque le fichier contient un nombre de lignes important.
Commande pour afficher le contenu d’un fichier HDFS
Exemple: Afficher dans le terminal le contenu du fichier « /user/hdoop/ml-100k/u.data » avec la commande tail.
Commande pour afficher le dernier kilo byte d’un fichier
Charger un fichier sur HDFS
Les commandes put et copyFromLocal permettent de charger un ou plusieurs fichiers du local sur HDFS. Les deux commandes sont similaires.
hdfs dfs -put <local src path> <dst path on HDFS>
hadoop fs -copyFromLocal <local src path> <dst path on HDFS>
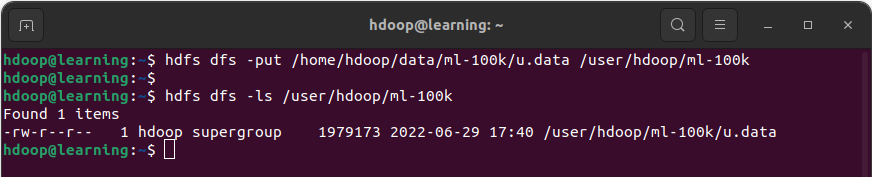
Exemple: Copier le fichier « u.info » dans /user/hdoop/ml-100k sur HDFS avec la commande put.
Commande pour copier un fichier du localhost sur HDFS (commande put)
Exemple: Copier les fichiers « u.user » et « u.item » dans /user/hdoop/ml-100K sur HDFS avec la commande copyFromLocal.
Commande pour copier des fichiers du localhost sur HDFS (commande copyToLocal)
Récupérer un fichier depuis HDFS
Les commandes get et copyToLocal permettent de récupérer des fichier HDFS sur votre local. Ces deux commandes fonctionnent de façon similaire.
Exemple: Copier le fichier « u.data » de HDFS dans un répertoire local (ici /home/hdoop/data/ml-100k_hdfs) avec la commande get.
Récupérer un fichier HDFS sur le localhost (commande get)
Exemple: Copier les fichier « u.user » et « u.item » de HDFS dans un répertoire local avec la commande copyToLocal.
Récupérer un fichier HDFS sur le localhost (commande copyToLocal)
Dans ces deux exemples, la commande ls sur votre localhost (ls /home/hdoop/ml-100k_hdfs) permet de retrouver les fichiers récupérés depuis votre système de fichier HDFS.
Déplacer un fichier
La commande mv est utilisée pour déplacer des fichiers sur HDFS.
hdfs dfs -mv <HDFS src path> <HDFS dst path>
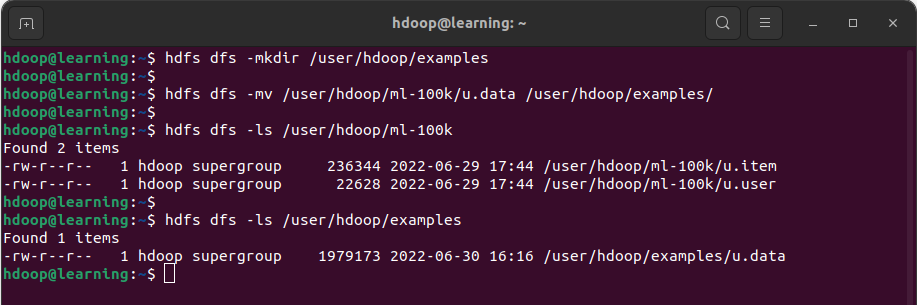
Exemple: Commencer par créer un répertoire /user/hdoop/examples en utilisant la commande mkdir. Puis déplacer le fichier « u.data » du dossier /user/hdoop/ml-100k vers /user/hdoop/examples en utilisant la commande mv.
Déplacer un fichier dans HDFS
La commande ls sur le répertoire HDFS source (/user/hdoop/ml-100k) montre que le fichier « u.data’ a bien été déplacé. Tandis que la commande ls sur le répertoire HDFS de destination(/user/hdoop/examples) montre que le fichier « u.data’ est présent.
Copier un fichier
La commande cp est utilisée pour copier des fichiers sur HDFS.
hdfs dfs -cp <HDFS src path> <HDFS dst path>
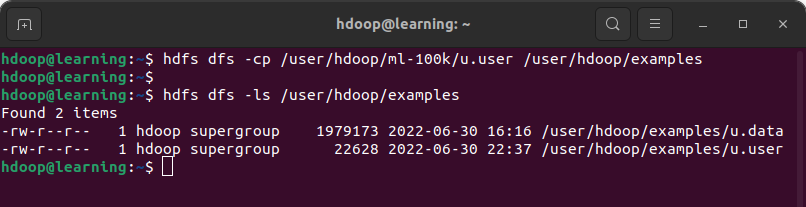
Exemple: Copier le fichier « u.user » du répertoire /user/hdoop/ml-100k vers /user/hdoop/examples
Copier un fichier dans HDFS
Supprimer un fichier
La commande rm permet de supprimer un fichier dans HDFS.
hdfs dfs -rm <HDFS file path>
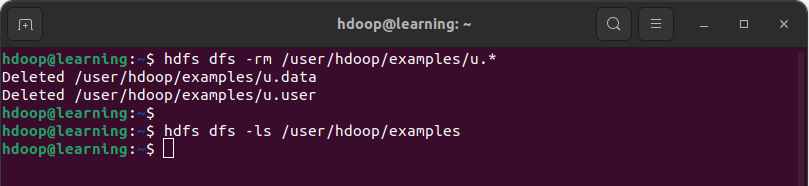
Exemple: Supprimer les fichiers conformes au pattern /user/hdoop/example/u.*
Supprimer un fichier dans HDFS
La commande ls permet de confirmer que le répertoire « /user/hdoop/examples » est dorénavant vide.
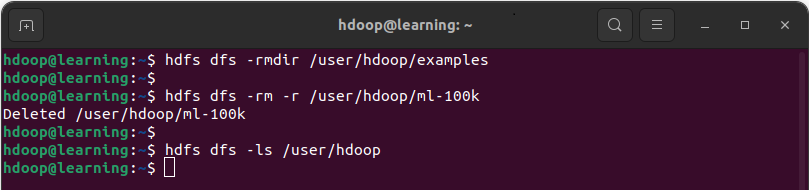
Supprimer un répertoire
La commande rmdir permet de supprimer un répertoire HDFS vide. Pour supprimer un répertoire non vide de manière récursive, il faut utiliser la commande rm -r.
hdfs dfs -rmdir <empty HDFS dir path>
hdfs dfs -rm -r <non empty HDFS dir path>
Exemple: Supprimer le répertoire vide « /user/hdoop/examples » avec la commande rmdir. Ensuite supprimer le répertoire non vide « /user/hdoop/ml-100k » avec la commande rm -r.
Supprimer un répertoire dans HDFS
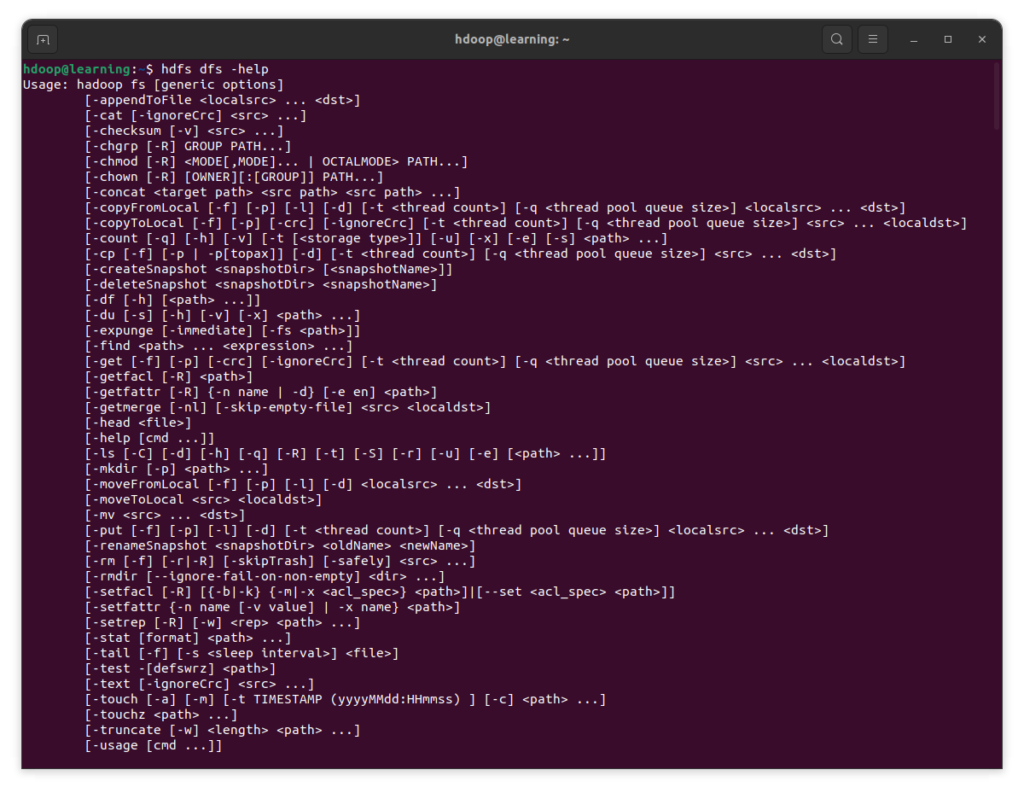
Liste complète des commandes HDFS
Pour une liste exhaustive des commandes disponibles sur HDFS, tapez la commande « hdfs dfs -help » pour les afficher dans le terminal. Pour chaque commande, les options disponibles sont indiquées.
Liste exhaustive des commandes HDFS
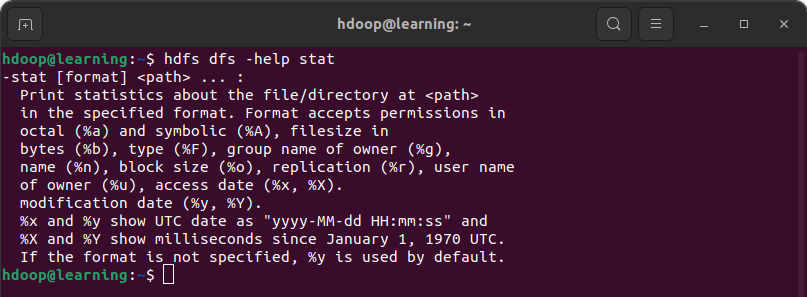
Pour afficher la documentation spécifique d’une commande, il suffit d’ajouter le nom de commande. Par exemple, la documentation de la commande stat s’obtient de la façon suivante:
Aide sur une commande HDFS (ici commande stat)
Interface Utilisateur
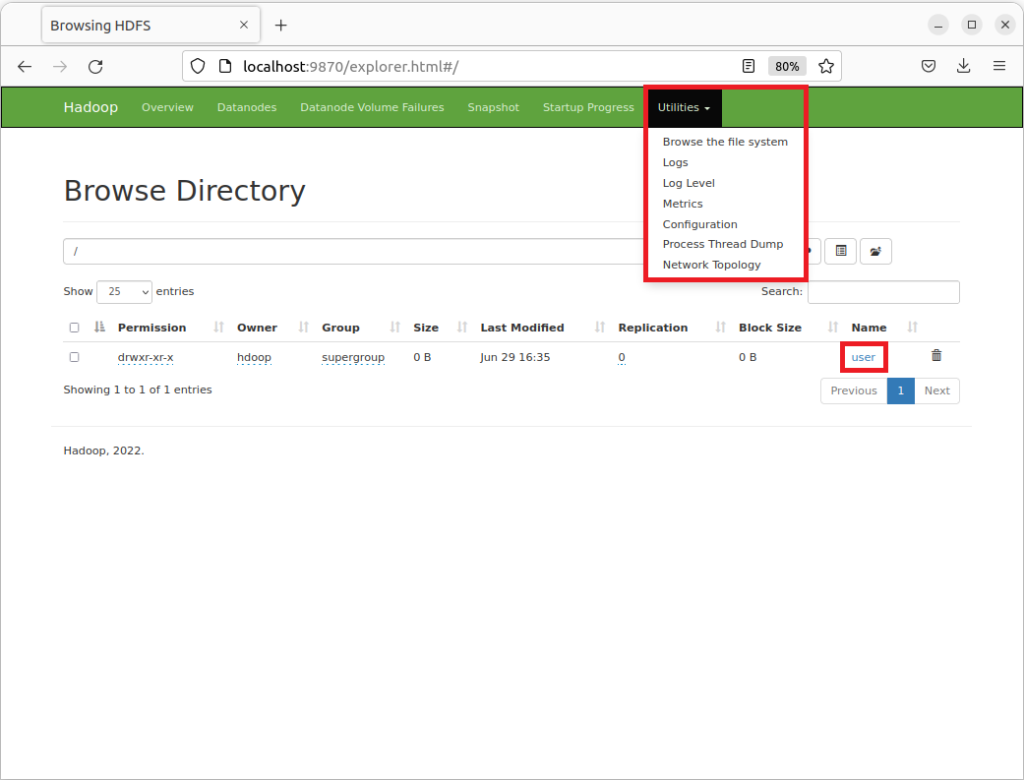
Apache Hadoop est fourni avec une interface utilisateur qui permet de visualiser le contenu de votre serveur Hadoop HDFS à la manière d’un explorateur de fichiers. Ouvrez votre navigateur web pour aller sur l’adresse http://localhost:9870. Cliquez sur le Menu « Utilities » puis sur l’onglet « Browse the file system« . Vous arrivez alors sur cette page:
Interface Utilisateur pour explorer les données HDFS
Vous pouvez alors naviguer dans les répertoires de système de fichiers. Sur l’image ci-dessus, vous retrouvez le répertoire « user/« .
En cliquant sur un fichier, un menu propose de télécharger ou bien de visualiser les premières ou dernières lignes du fichier dans l’interface.
Interface Utilisateur: information sur les fichiers
Conclusion
Félicitations, vous avez réalisé vos premières manipulations sur HDFS en ligne de commandes.
L’objectif de ce tutoriel est de vous permettre de réaliser l’installation complète de Apache Hadoop sous Ubuntu.
Dans le cas présent, les versions utilisées sont les suivantes: Hadoop en version 3.3.3 et Ubuntu 22.01.
Ce tutoriel se veut être pédagogique. C’est pour cela que nous allons détailler chacune des étapes de l’installation.
Une fois arrivé à la fin de ce tutoriel, vous disposerez d’un environnement complet pour commencer à tester vos développements Hadoop.
Cet article fait partie d’un ensemble d’articles sur l’écosystème Hadoop.
Etapes de l’installation
Voici les étapes nécessaires pour réaliser notre installation de Apache Hadoop:
Vérifier les prérequis
Créer un groupe d’utilisateur Hadoop
Configurer SSH
Télécharger Hadoop
Ajouter les variables d’environnement pour Hadoop
Configurer les composants Hadoop
Initialiser le système de fichier HDFS
Démarrer le serveur Hadoop
Tester l’installation
Arrêter le serveur Hadoop
Vérifier les prérequis
Hadoop a deux prérequis: Java et SSH.
Si vous disposez déjà de Java 8 et de SSH sur votre machine, vous pouvez ignorez les deux paragraphes suivants.
Avant de commencer les installations sur Ubuntu, mettez à jour le cache des paquets de vos dépôts avec la commande:
sudo apt-get update
JAVA
Hadoop est développé en Java d’où le besoin qu’une version compatible soit installée sur votre machine. Pour connaître la version de Java compatible avec la version d’Hadoop, il est conseillé de consulter la page wiki d’Hadoop. Dans ce tutoriel, nous allons installer Hadoop en version 3.3.3 supporté par Java 8. Pour commencer, ouvrez un terminal et entrez les commandes suivantes:
sudo apt install openjdk8-jdk
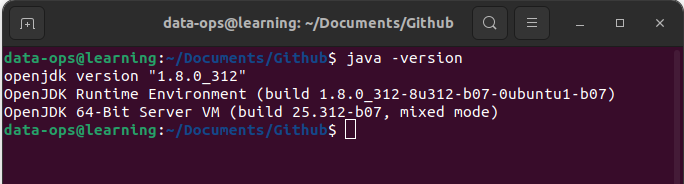
Une fois l’installation de Java terminée, utilisez la commande « java -version » pour vérifier que Java est installé en version 8. Cette commande doit vous retourner un message dans votre terminal du type:
Vérifier la version de Java installée
SSH
Pour utiliser les scripts de lancement et d’arrêt des démons d’Hadoop, vous devez installer SSH. Pour cela, tapez la commande suivante dans un terminal:
sudo apt install ssh
Créer un groupe d’utilisateur Hadoop
Bien que cette étape soit facultative, elle permet de séparer les installations de logiciels pour assurer la sécurité et gérer les permissions. Ainsi, il est conseillé de créer un groupe hadoop et un utilisateur spécifique hdoop avec un accès administrateur. Cela est réalisé avec les trois commandes suivantes:
Une fois l’utilisateur hdoop créé, connectez vous avec cet utilisateur de la façon suivante:
su - hdoop
Configurer SSH
Hadoop a besoin d’un accès SSH à tous les nœuds. Même en mode pseudo distribué sur un seul nœud, on doit donner accès au localhost à l’utilisateur hdoop. Pour cela, nous allons commencer par générer une clé SSH pour l’utilisateur hdoop avec la commande suivante:
ssh-keygen -t rsa -P ''
Puis nous devons autoriser l’accès SSH au localhost pour cette nouvelle clé RSA:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
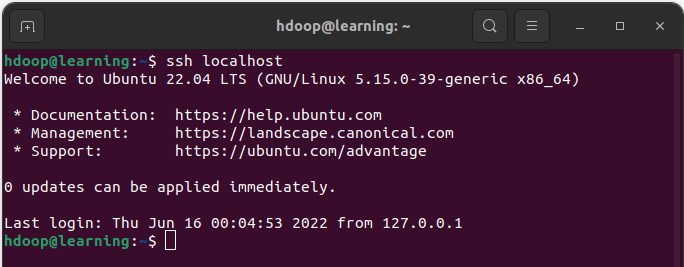
Enfin, vous pouvez vérifier que la connexion SSH au localhost pour l’utilisateur hdoop fonctionne correctement avec la commande « ssh localhhost » qui devra vous retourner un message du type:
Connexion SSH réussie au localhost pour l’utilisateur hdoop
Télécharger Hadoop
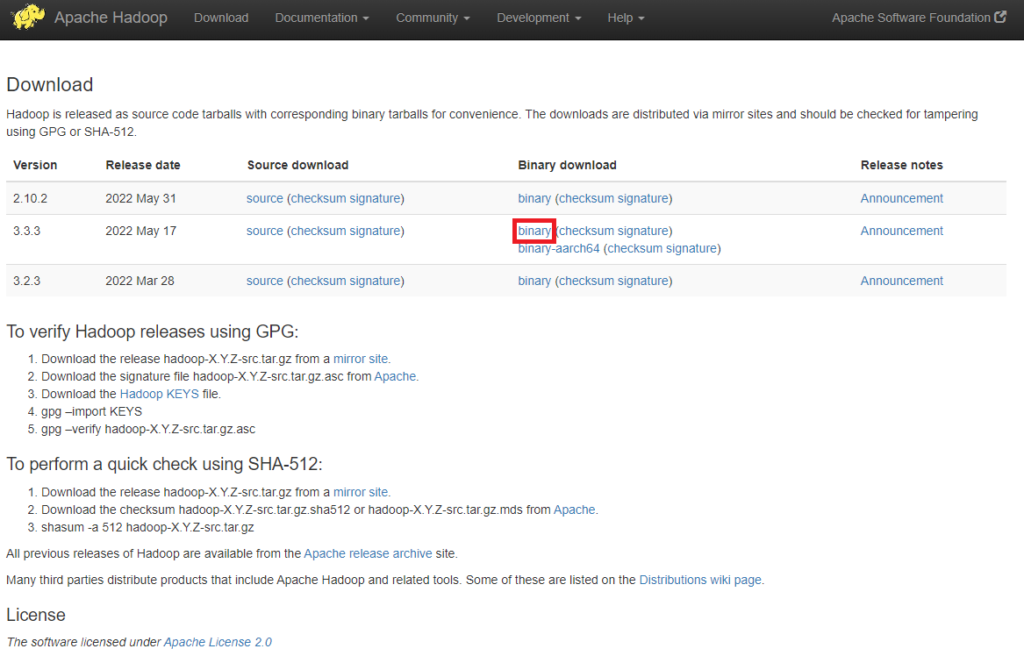
Il est conseillé d’utiliser le site officiel d’Apache Hadoop pour télécharger une version stable de Hadoop. Dans ce tutoriel, nous allons utiliser le binaire de Hadoop en version 3.3.3.
Page de téléchargement sur le site Apache Hadoop
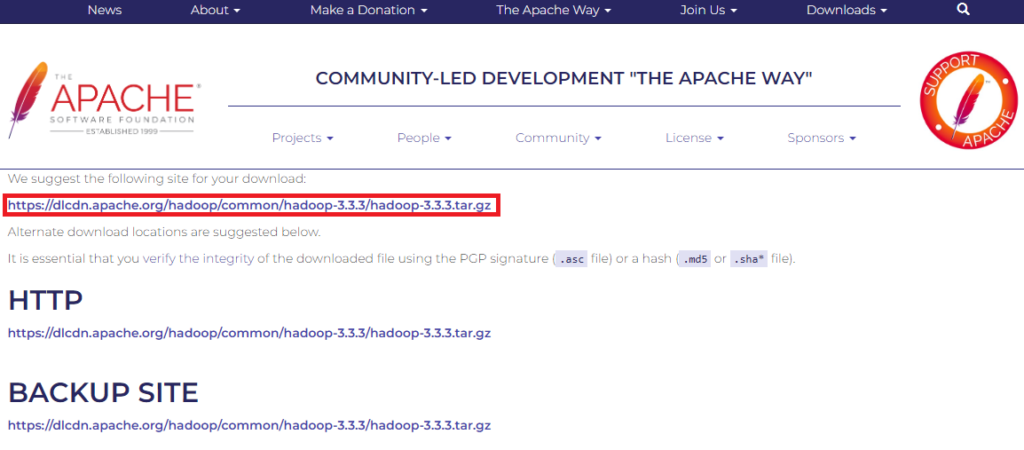
Lien du miroir de téléchargement de Apache Hadoop
Utilisez le miroir suggéré pour lancer le téléchargement via la commande wget.
Ensuite vous pourrez extraire les fichiers du fichier compressé .tar.gz en utilisant la commande tar. Enfin assurez vous que le répertoire « hadoop-3.3.2 » est positionné dans /usr/local. Les commandes suivantes vous permettent de réaliser ces opérations:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.3/hadoop-3.3.3.tar.gz
tar -xvf hadoop-3.3.2.tar.gz
mv hadoop-3.3.2 /usr/local/
Ajouter les variables d’environnement pour Hadoop
Des variables d’environnements ont besoin d’être ajouté au fichier .bashrc pour définir les répertoires d’Hadoop. Ouvrez le fichier .bashrc dans un éditeur de texte et ajoutez les lignes suivantes:
Tapez la commande la commande « source .basrc » dans un terminal pour recharger ces nouvelles variables d’environnement. Enfin vérifiez que la variable $HADOOP_HOME renvoie le chemin du répertoire où Hadoop a été positionné avec la commande « echo »:
Affichage de la variable d’environnement $HADOOP_HOME
Modifier les variables d’environnement d’Hadoop
Nous allons modifier la variable JAVA_HOME pour indiquer à Hadoop quelle version de java installée est à utiliser. En l’occurence ici, il s’agit de Java 8 conformément au prérequis. Ouvrez le fichier $HADOOP_HOME/etc//hadoop/hadoop-env.sh pour modifier la variable JAVA_HOME comme ceci:
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
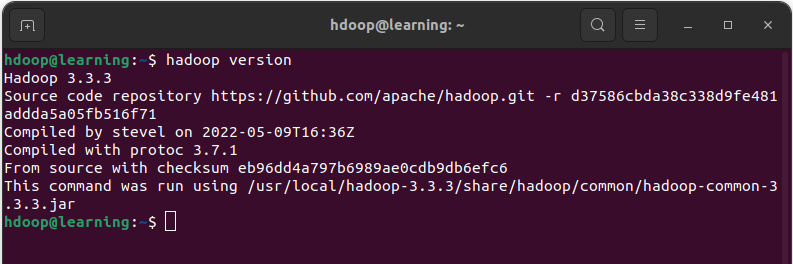
A présent en tapant dans un terminal la commande « hadoop version« , vous devez avoir un message du type:
Retour de la commande « hadoop version »
Configurer les composants de Hadoop
La configuration de chacun des composants de Hadoop est définie à partir de fichiers XML. Les propriétés communes de votre installation Hadoop sont faites dans le fichier core-site.xml. Et les différents composants HDFS, MapReduce et YARN sont paramétrés respectivement dans les fichiers hdfs-site.xml, mapred-site.xml et yarn-site.xml. L’ensemble de ces fichiers se trouvent dans le répertoire de votre installation $HADOOP_HOME/etc/hadoop. Pour chacun de ces fichiers, nous allons voir les paramètres qu’il est nécessaire de renseigner.
Hadoop Core
Ouvrez le fichier core-site.xml pour modifier les deux variables:
hadoop.tmp.dir: répertoire contenant tout les fichiers de travail de Hadoop,
Avant de lancer votre serveur Hadoop, vous devez formater le système de fichier HDFS. Toujours en utilisant l’utilisateur hdoop, exécutez dans un terminal la commande suivante:
hdfs namenode -format
Démarrer le serveur Hadoop
A présent, vous allez pouvoir démarrer votre serveur Hadoop en deux étapes.
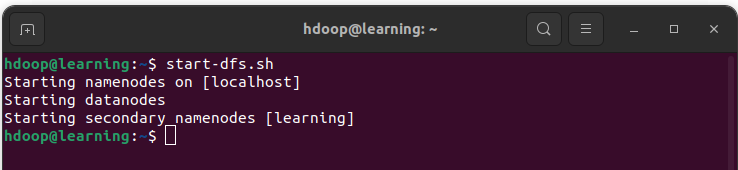
Pour démarrer le namenode et le datanode, vous devez lancer le démon HDFS avec la commande:
start-dfs.sh
Démarrage des démons HDFS
Pour démarrer YARN et le NodeManagers, vous devez lancer le démon YARN avec la commande:
start-yarn.sh
Démarrage des démons YARN et du NodeManager
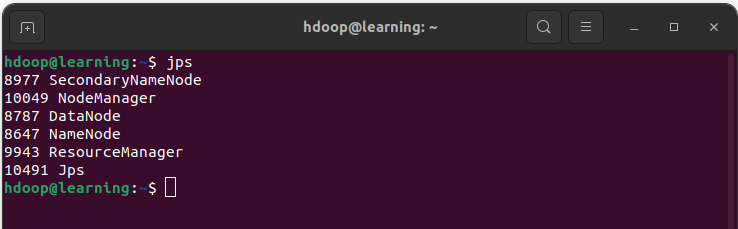
Afin de vous assurer que tous les démons sont actifs et s’exécutent en tant que processus Java, exécutez la commande « jps » dans un terminal. Cette commande doit vous retourner des messages similaires à:
Commande « jps » pour vérifier que tout les processus s’exécutent correctement
Tester l’installation
Une fois l’ensemble des démons démarrés, il est également possible de vérifier leur bon fonctionnement via trois interfaces utilisateurs incluses dans l’installation d’Hadoop:
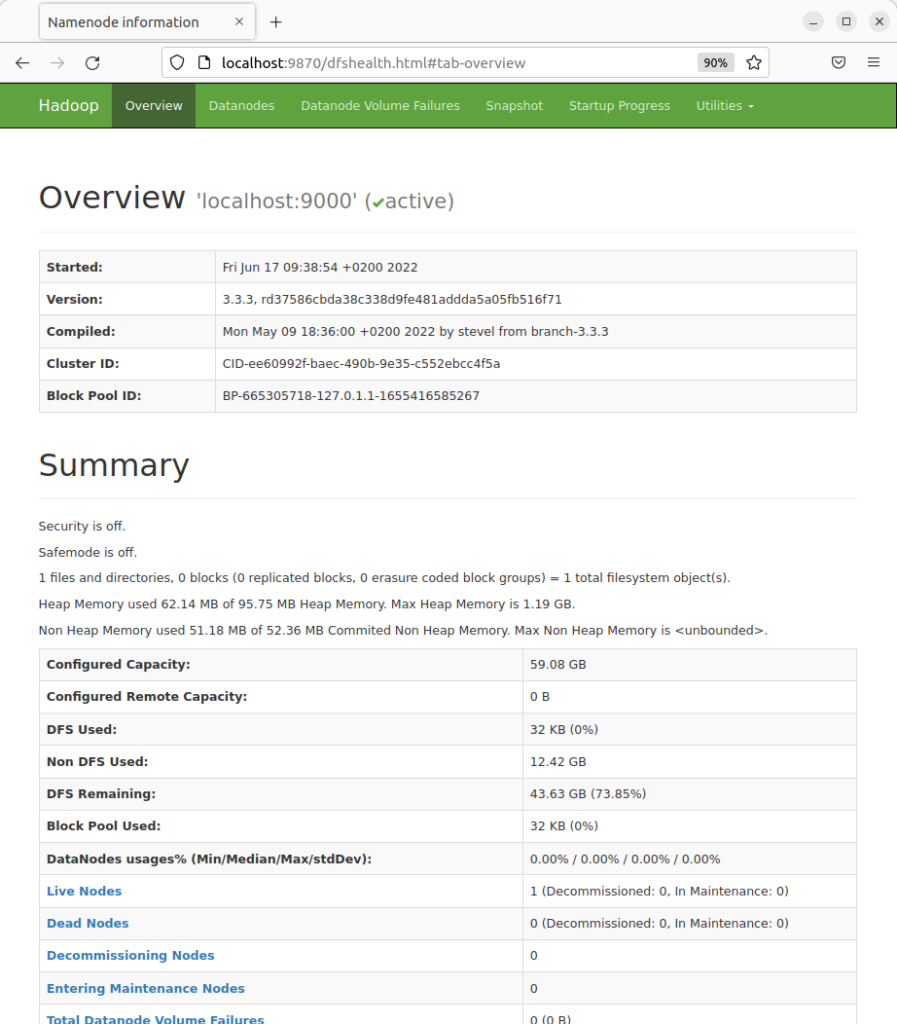
Hadoop NameNode: http://localhost:9870
Interface utilisateur pour le NameNode
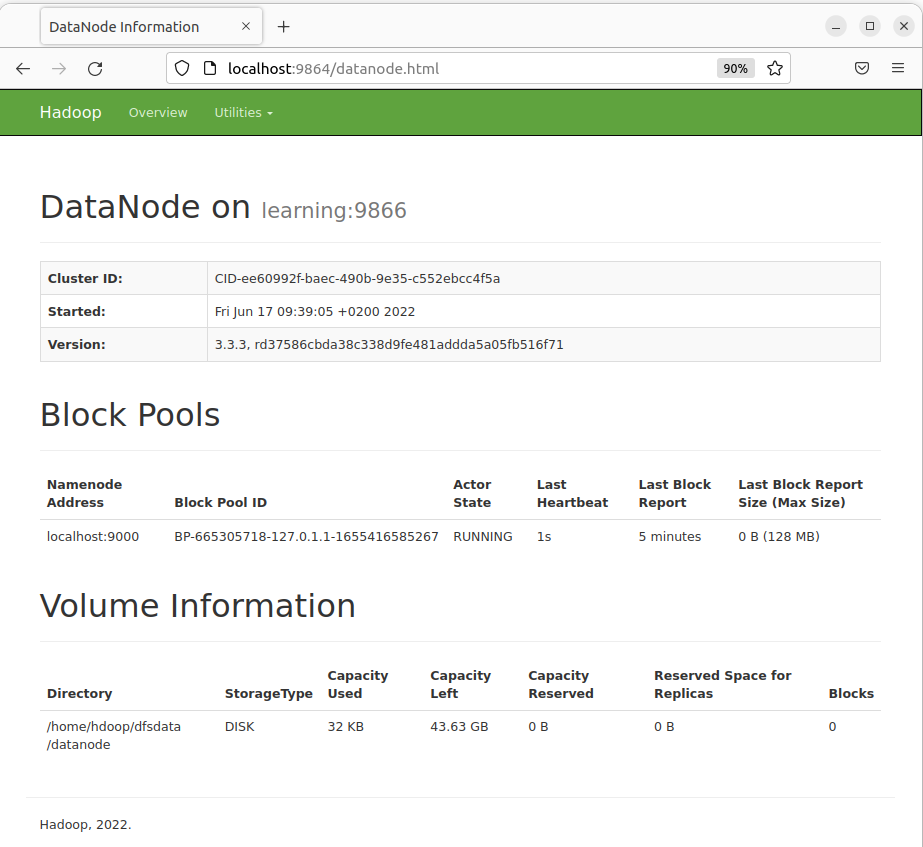
Individual DataNodes: http://localhost:9864
Interface utilisateur pour le DataNode
YARN ResourceManager: http://localhost:8088
Interface utilisateur pour YARN
Arrêter le serveur Hadoop
L’arrêt du serveur Hadoop se fait par des commandes spécifiques comme pour le démarrage du serveur.
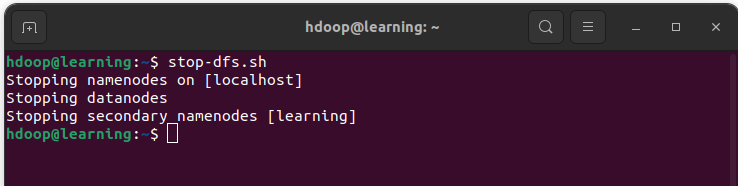
Arrêtez les démons HDFS avec la commande suivante:
stop-dfs.sh
Arrêt des démons HDFS
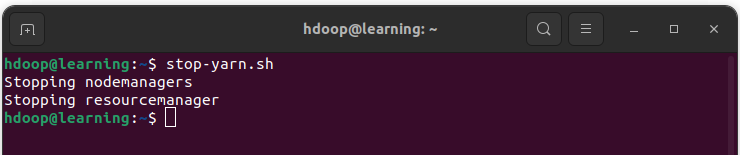
Arrêtez les démons YARN avec la commande suivante:
stop-yarn.sh
Arrêt des démons YARN
Conclusion
Félicitations, vous avez maintenant une installation complète et opérationnelle de Apache Hadoop. Vous pouvez commencer à tester vos développements dans l’écosystème Hadoop.
Pour aller plus loin, vous pouvez consulter nos articles:
Cet article va vous présenter comment écrire un programme MapReduce Hadoop en utilisant le langage de programmation Python.
Hadoop est développé en Java et permet d’écrire des programmes map/reduce en Java. Mais il est tout à fait possible d’écrire des applications MapReduce dans d’autres langages en utilisant l’API Hadoop Streaming. Cette API prend en charge tous les langages qui peuvent lire à partir de l’entrée standard et écrire sur la sortie standard.
Nous allons également devoir manipuler des fichiers sur le serveur HDFS. Les commandes à exécuter seront données. Toutefois, vous pouvez consulter l’article Manipuler vos fichiers sur HDFS en ligne de commandes pour en savoir plus.
Nous allons utiliser des scripts python exécutables pour définir le mapper et le reducer. Vous devrez renseigner en tête de chaque script Python le chemin vers l’interpréteur python de la forme: #!/usr/bin/python3 (à personnaliser suivant l’interpréteur Python que vous souhaitez utiliser).
Description du problème à résoudre
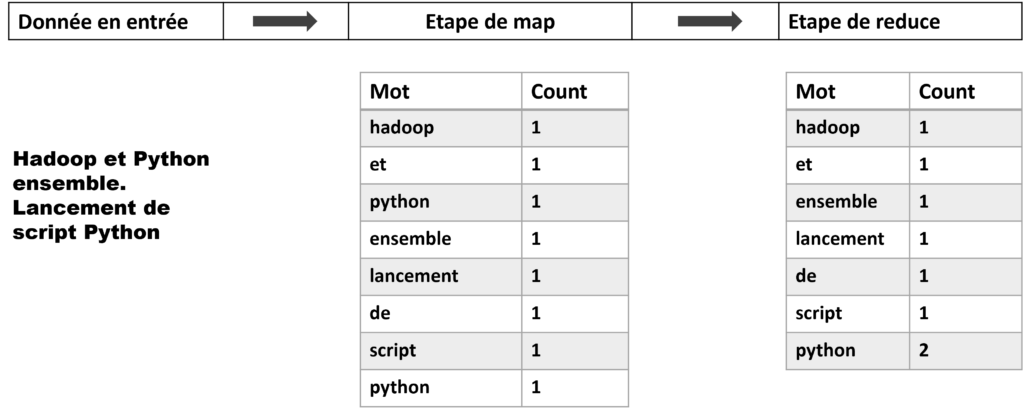
Nous allons reprendre le problème classique de comptage du nombre d’occurrences des mots dans des fichiers textes. Le programme reçoit en entrée des fichiers textes. L’étape du map permet d’associer à chaque terme le nombre 1. En sortie de l’étape de reduce, un fichier texte est produit et contiendra sur chaque ligne un mot et le nombre d’occurrences de ce mot séparé par une tabulation.
Schéma de calcul du comptage en MapReduce
Programme MapReduce écrit en Python
Nous allons présenter les deux scripts qui vont servir de mapper et de reducer pour l’application MapReduce que nous cherchons à mettre en place. Les deux scripts seront sauvegardés dans /home/hdoop/Documents/hadoop-stremaing/
Etape de Map
Copiez et sauvegardez ce code dans un script mapper.py. Ce script lit à partir de l’entrée standard STDIN (commande sys.stdin) les données. Chaque ligne va être divisée en mot et retournée sous forme de tuple sur la sortie standard STDOUT. Chaque tuple sera de la forme « <mot> 1 ». Il s’agit évidemment d’un comptage intermédiaire étant donné qu’un mot peut être répété plus d’une fois. Le comptage final par mot sera calculé par le reducer dans l’étape suivante.
#!/usr/bin/python3.10
import re
import sys
for line in sys.stdin:
# suppression des espaces en début et fin de ligne
line = line.strip()
# suppression de la ponctuation et mise en minuscule
line = re.sub(r"[^\w\s]", ' ', line.lower())
# division des lignes en mots
words = line.split()
for word in words:
# écriture des résultats en STDOUT avec des tabulations en délimiteur
print(f"{word.lower()} \t 1")
Etape de Reduce
Copiez et sauvegardez ce code dans un script reducer.py. Ce script lit à partir de l’entrée standard STDIN les sorties du script mapper.py. Les occurrences de chaque mot sont agrégées et écrites sur la sortie standard STDOUT.
#!/usr/bin/python3
import sys
current_word = None
current_count = 0
word = None
# lecture depuis l'entrée standard STDIN
for line in sys.stdin:
# suppression des espaces en début et fin de ligne
line = line.strip()
# divise une chaîne de caractère issus du mapper.py
# en une liste sur la tabulation
word, count = line.split('\t', 1)
# convertit la variable count en entier (string initialement)
try:
count = int(count)
except ValueError:
# si count n'est pas un nombre, on ignore la ligne
continue
# trie la sortie de mapperpy par Hadoop par mot
# avant d'être traité par le reducer
if current_word == word:
current_count += count
else:
if current_word:
# écriture du résultat sur la sortie standard STDOUT
print(f"{current_word}\t{current_count}")
current_count = count
current_word = word
# écriture du résultat du dernier mot sur la sortie
# standard STDOUT si besoin
if current_word == word:
print(f"{current_word}\t{current_count}")
Tester son code en local
Avant d’utiliser Hadoop Streaming, il est conseillé tester ces deux scripts Python. Au préalable, il faut changer les permissions de ces deux fichiers en donnant à l’utilisateur l’autorisation de les exécuter:
chmod u+x mapper.py
chmod u+x reducer.py
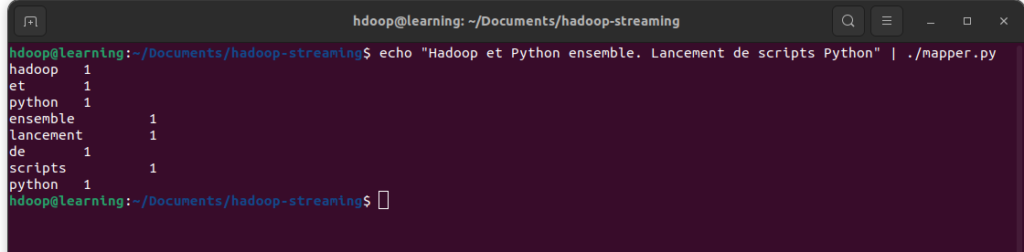
Nous allons commencer par tester le mapper en utilisant une phrase simple de test: « Hadoop et Python ensemble. Lancement de scripts Python ». Entrez la commande suivante dans un terminal:
echo "Hadoop et Python ensemble. Lancement Script Python" | ./mapper.py
Test du script mapper.py en ligne de commande
On retrouve le résultat attendu: chaque mot est associé à la valeur 1. Le mot « Python » étant répété deux fois dans la phrase de test et il apparaît donc deux fois dans le résultat sous la forme: « python 1 ».
Enfin pour reproduire le comportement de Hadoop en streaming, nous pouvons tester le processus de MapReduce avec la commande suivante:
Test des scripts mapper.py et reducer.py en ligne de commande
On retrouve dans ce cas pour chaque mot, son nombre d’occurrence dans la phrase simple qui a été testée. Le mot « Python » apparaît dans le résultat final sour la forme « python 2 » car il apparaît deux fois.
Exécuter un job Streaming MapReduce
Dans cette section, nous allons décrire les étapes pour exécuter un exemple complet en utilisant Hadoop Streaming.
Télécharger les données d’entrée
Pour réaliser un test plus complet, nous proposons d’utiliser des livres mis à disposition gratuitement par le projet Gutenberg:
Utilisez chaque lien pour télécharger la version texte au format Plain Text UTF-8.
Copier les données d’entrée sur HDFS
Les données à traiter avec Hadoop Streaming doivent être placé sur HDFS. Pour cela, vous devez les copier depuis votre local sur HDFS en utilisant la commande « hdfs dfs -copyFromLocal » de la façon suivante:
Copie des fichiers tests sur HDFS
Dans cet exemple, les répertoires sont définis comme :
en local: « /home/hdoop/Documents/data/gutenberg« . Répertoire dans lequel les fichiers du projet Gutenberg ont été sauvegardés.
sur HDFS: « /user/hdoop/gutenberg« . Répertoire sur HDFS dans lequel les fichiers sont copiés.
Exécuter le processus avec Hadoop MapReduce
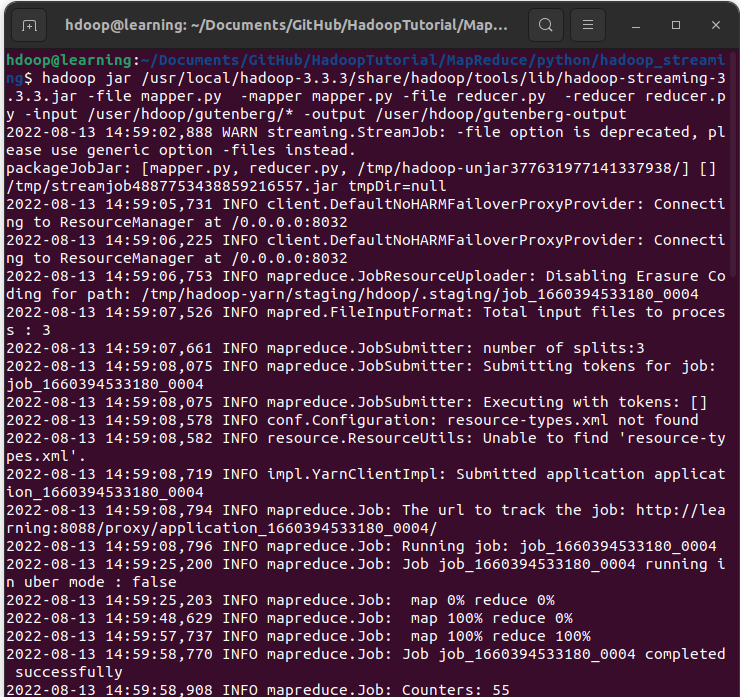
Depuis le répertoire dans lequel vous avez sauvegardé les scripts mapper.py et reducer.py, nous allons lancer la commande Hadoop pour exécuter ce job en streaming MapReduce. Dans un terminal, tapez la commande suivante:
Vous pouvez voir ici que nous avons utilisé le jar hadoop-streaming-3.3.3 qui correspond à celui de la version d’Hadoop 3.3.3. Modifiez-le en fonction de la version de Hadoop installée sur votre machine si différente.
Les options de bases utilisées pour cette commande sont les suivantes:
Option
Description
-mapper
commande à exécuter pour le map
-reducer
commande à exécuter pour le reduce
-input
le path sur HDFS contenant les données d’entrée du mapper
-output
le path HDFS pour l’écriture des résultats du reducer
-file
chemin des exécutables en local mis à disposition des nœuds de calculs
Options de la commande Hadoop MapReduce
Exécution d’un processus MapReduce avec Hadoop Streaming
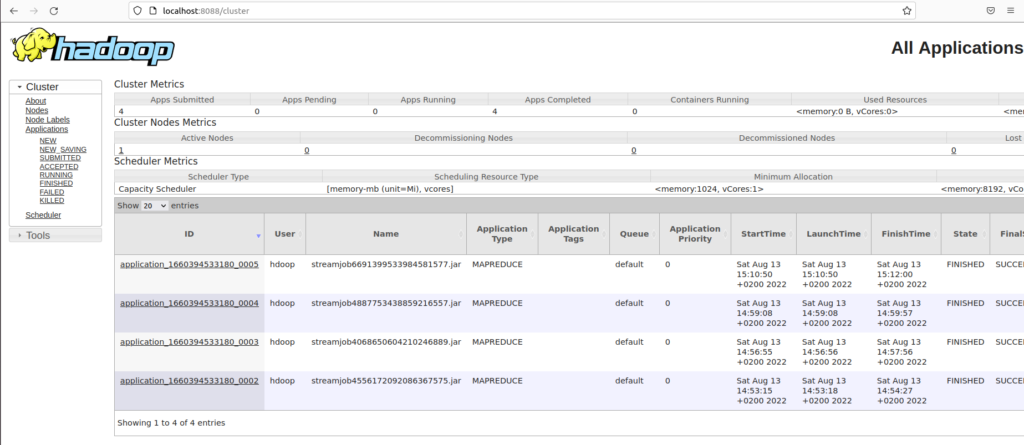
Une fois le processus Hadoop lancé, il est possible de le monitorer depuis l’interface http://localhost:8088/. Elle donne plusieurs informations comme le détail des processus en cours, terminé en succès ou en échec et un ensemble d’information utile pour monitorer vos calculs.
Monitoring des processus MapReduce depuis l’interface web
Conclusion
Félicitations, vous avez dorénavant les connaissances nécessaire pour développer vos programmes MapReduce en Python. Et vous savez comment comment les exécuter en utilisant l’API Hadoop Streaming.